Other Frameworks
Overview
The ads.model.generic_model.GenericModel class in ADS provides an efficient way to serialize almost any model class. This section demonstrates how to use the GenericModel class to prepare model artifacts, verify models, save models to the model catalog, deploy models, and perform predictions on model deployment endpoints.
The GenericModel class works with any unsupported model framework that has a .predict() method. For the most common model classes such as scikit-learn, XGBoost, LightGBM, TensorFlow, and PyTorch, and AutoML, we recommend that you use the ADS provided, framework-specific serializations models. For example, for a scikit-learn model, use SKLearnmodel. For other models, use the GenericModel class.
The .verify() method simulates a model deployment by calling the load_model() and predict() methods in the score.py file. With the .verify() method, you can debug your score.py file without deploying any models. The .save() method deploys a model artifact to the model catalog. The .deploy() method deploys a model to a REST endpoint.
These simple steps take your trained model and will deploy it into production with just a few lines of code.
Prepare Model Artifact
Instantiate a GenericModel() object by giving it any model object. It accepts the following parameters:
artifact_dir: str: Artifact directory to store the files needed for deployment.auth: (Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. To override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal()and create the appropriate authentication signer and the**kwargsrequired to instantiate theIdentityClientobject.estimator: (Callable): Trained model.properties: (ModelProperties, optional): Defaults toNone. ModelProperties object required to save and deploy the model.serialize: (bool, optional): Defaults toTrue. IfTruethe model will be serialized into a pickle file. IfFalse, you must set themodel_file_namein the.prepare()method, serialize the model manually, and save it in theartifact_dir. You will also need to update thescore.pyfile to work with this model.
The properties is an instance of the ModelProperties class and has the following predefined fields:
bucket_uri: strcompartment_id: strdeployment_access_log_id: strdeployment_bandwidth_mbps: intdeployment_instance_count: intdeployment_instance_shape: strdeployment_log_group_id: strdeployment_predict_log_id: strdeployment_memory_in_gbs: Union[float, int]deployment_ocpus: Union[float, int]inference_conda_env: strinference_python_version: stroverwrite_existing_artifact: boolproject_id: strremove_existing_artifact: booltraining_conda_env: strtraining_id: strtraining_python_version: strtraining_resource_id: strtraining_script_path: str
By default, properties is populated from the environment variables when not specified. For example, in notebook sessions the environment variables are preset and stored in project id (PROJECT_OCID) and compartment id (NB_SESSION_COMPARTMENT_OCID). So properties populates these environment variables, and uses the values in methods such as .save() and .deploy(). Pass in values to overwrite the defaults. When you use a method that includes an instance of properties, then properties records the values that you pass in. For example, when you pass inference_conda_env into the .prepare() method, then properties records the value. To reuse the properties file in different places, you can export the properties file using the .to_yaml() method then reload it into a different machine using the .from_yaml() method.
Summary Status
You can call the .summary_status() method after a model serialization instance such as AutoMLModel, GenericModel, SklearnModel, TensorFlowModel, or PyTorchModel is created. The .summary_status() method returns a Pandas dataframe that guides you through the entire workflow. It shows which methods are available to call and which ones aren’t. Plus it outlines what each method does. If extra actions are required, it also shows those actions.
The following image displays an example summary status table created after a user initiates a model instance. The table’s Step column displays a Status of Done for the initiate step. And the Details column explains what the initiate step did such as generating a score.py file. The Step column also displays the prepare(), verify(), save(), deploy(), and predict() methods for the model. The Status column displays which method is available next. After the initiate step, the prepare() method is available. The next step is to call the prepare() method.
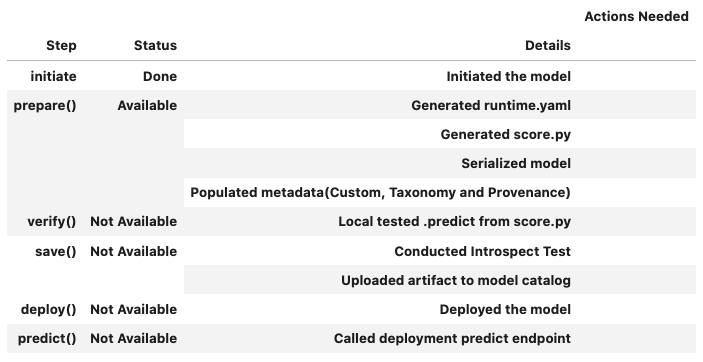
Example
By default, the GenericModel serializes to a pickle file. The following example, the user creates a model. In the prepare step, the user saves the model as a pickle file with the name toy_model.pkl. Then the user verifies the model, saves it to the model catalog, deploys the model and makes a prediction. Finally, the user deletes the model deployment and then deletes the model.
import tempfile
from ads.model.generic_model import GenericModel
class Toy:
def predict(self, x):
return x ** 2
model = Toy()
generic_model = GenericModel(estimator=model, artifact_dir=tempfile.mkdtemp())
generic_model.summary_status()
generic_model.prepare(
inference_conda_env="dbexp_p38_cpu_v1",
model_file_name="toy_model.pkl",
force_overwrite=True
)
# Check if the artifacts are generated correctly.
# The verify method invokes the ``predict`` function defined inside ``score.py`` in the artifact_dir
generic_model.verify(2)
# Register the model
model_id = generic_model.save(display_name="Custom Model")
# Deploy and create an endpoint for the XGBoost model
generic_model.deploy(
display_name="My Custom Model",
deployment_log_group_id="ocid1.loggroup.oc1.xxx.xxxxx",
deployment_access_log_id="ocid1.log.oc1.xxx.xxxxx",
deployment_predict_log_id="ocid1.log.oc1.xxx.xxxxx",
)
print(f"Endpoint: {generic_model.model_deployment.url}")
# Generate prediction by invoking the deployed endpoint
generic_model.predict(2)
# To delete the deployed endpoint uncomment the line below
# generic_model.delete_deployment(wait_for_completion=True)
You can also use the shortcut .prepare_save_deploy() instead of calling .prepare(), .save() and .deploy() seperately.
import tempfile
from ads.model.generic_model import GenericModel
class Toy:
def predict(self, x):
return x ** 2
estimator = Toy()
model = GenericModel(estimator=estimator)
model.summary_status()
# If you are running the code inside a notebook session and using a service pack, `inference_conda_env` can be omitted.
model.prepare_save_deploy(inference_conda_env="dbexp_p38_cpu_v1")
model.verify(2)
# Generate prediction by invoking the deployed endpoint
model.predict(2)
# To delete the deployed endpoint uncomment the line below
# model.delete_deployment(wait_for_completion=True)