Release Notes
April 1, 2022
ADS v2.5.9
ADS
Added framework specific model serialization to add more inputs to the generated
score.pyfile.Added the following framework-specific model classes:
AutoMLModelSKlearnModelXGBoostModelLightGBMModelPyTorchModelTensorFlowModel
For any framework not included in the preceding list, added another class:
GenericModel
These model classes include methods specific to the frameworks that improve deployment speed. Some example methods are:
Prepare (the artifacts)
Save (metadata and model to model catalog)
Deploy (the models quickly with this method)
Predict (perform inference operations)
Added support to create jobs with managed egress.
Shortened the time for streaming large number of logs for job run logging.
March 3, 2022
ADS v2.5.8
ADS
Fixed bug in automatic extraction of taxonomy metadata for
Sklearnmodels.Fixed bug in jobs
NotebookRuntimewhen using non-ASCII encoding.Added compatibility with Python
3.8and3.9.Added an enhanced string class, called
ADSString. It adds functionality such as regular expression (RegEx) matching, and natural language processing (NLP) parsing. The class can be expanded by registering custom plugins to perform custom string processing actions.
February 4, 2022
ADS v2.5.7
ADS
Fixed bug in DataFlow
Jobcreation.Fixed bug in ADSDataset
get_recommendationsraisingHTML is not definedexception.Fixed bug in jobs
ScriptRuntimecausing the parent artifact folder to be zipped and uploaded instead of the specified folder.Fixed bug in
ModelDeploymentraisingTypeErrorexception when updating an existing model deployment.
January 21, 2022
ADS v2.5.6
ADS
Added support for the
storage_optionsparameter in ADSDataset.to_hdf().Fixed error message to specify
overwrite_scriptoroverwrite_archiveoption indata_flow.create_app().Fixed output of multiclass evaluation plots when
ADSEvaluatior()class uses a non-defaultlegend_labelsoption.Added support to connect to an Oracle Database that does not require a wallet file.
Added support to read and write from MySQL using ADS DataFrame APIs.
December 9, 2021
ADS v2.5.5
ADS
Fixed bug in model artifact
prepare(),reload(), andprepare_generic_model()raisingONNXRuntimeErrorcaused by the mismatched version ofskl2onnx.
December 3, 2021
ADS v2.5.4
The following features were added:
Data Labeling
Added support to read exported dataset from the consolidated export file.
Following fixes were added:
ADS
The
DaskSeriesclass was marked as deprecated.The
DaskSeriesAccessorclass was marked as deprecated.The
MLRuntimeclass was marked as deprecated.The
ADSDataset.ddfattribute was marked as deprecated.
November 29, 2021
ADS v2.5.3
The following features were added:
ADS
Moved
fastavro,pandavroandopenpyxlto an optional dependency.
Data Labeling
Added the ability to specify the output annotation format to be
spacyfor the Entity Extraction dataset oryolofor the Object Detection dataset.Added support to load labeled dataset from OCI Data Labeling, and return the Pandas dataframe or generator formats.
Added support to load labeled datasets by chunks.
November 17, 2021
ADS v2.5.2
The following features were added:
ADS
Added support to manage credentials with the OCI Vault service for
ADBandAccess Tokens.Improved model introspection functionality. The
INFERENCE_ENV_TYPEandINFERENCE_ENV_SLUGparameters are no longer required.Updated ADS dependency requirements. Relaxed the versions for the
scikit-learn,scipyandonnxdependencies.Moved
dask,ipywidgetandwordcloudto an optional dependency.The
Boston Housingdataset was replaced with an alternative one.Migrated
ADSDatasetto use Pandas instead of Dask.Deprecated
MLRuntime.Deprecated
resource_analyzemethod.
Jobs
Added support for magic commands in notebooks when they run in a job.
Added support to download notebook and output after running it in a job.
October 20, 2021
ADS v2.5.0
The following features were added:
Data Labeling
Integrating with the Oracle Cloud Infrastructure Data Labeling service.
Listing labeled datasets in the Data Labeling service.
Exporting labeled datasets into Object Storage.
Loading labeled datasets in the Pandas dataframe or generator formats.
Visualizing the labeled entity extraction and object detection data.
Converting the labeled entity extraction and object detection data to the Spacy and YOLO formats respectively.
ADS v2.4.2
The following improvements were effected:
ADS
Improve ads import time.
Fix the version of the jsonschema package.
Update numpy deps to >= 1.19.2 for compatibility with TensorFlow 2.6.
Data Flow
Added progress bar when creating a Data Flow application.
Fixed the file upload path in Data Flow.
Model Store
Added supporting tags when saving model artifacts.
Model Deployment
Updated Model Deployment authentication.
This release has following bug fixes:
ADS
Fixed the default
runtime.yamltemplate generated outside of a notebook session.Oracle DB mixinthe batch size parameter is now passed downstream.ADSModel.prepare()andprepare_generic_model()force_overwrite deletes user created folders.prepare_generic_modelfails to create a successful artifact when taxonomy is extracted.
Dataflow
Specify spark version in
prepare_app()now works.
Jobs
Running Job from a ZIP or folder now works.
September 27, 2021
ADS v2.4.1
The following dependencies were removed:
pyarrowpython-snappy
September 22, 2021
ADS v2.4.0
Jobs
The Data Science jobs feature is introduced and includes the following:
Data Science jobs allow data scientists to run customized tasks outside of a notebook session.
Running Data Science jobs and Data Flow applications through unified APIs by configuring job infrastructure and runtime parameters.
Configuring various runtime configurations for running code from Python/Bash script, packages including multiple modules, Jupyter notebook, or a Git repository.
Monitoring job runs and streaming log messages using the Logging service.
September 20, 2021
ADS v2.3.4
This release has following bug fixes:
prepare_generic_modelfails when used outside the Data Science notebook sessionTextDatasetFactoryfails when used outside the Data Science notebook session
September 17, 2021
ADS v2.3.3
Removed dependency on plotly
print_user_message replaced with logger
August 3, 2021
ADS v2.3.1
Model Catalog
This release of the model catalog includes these enhancements:
Automatical extraction of model taxonomy metadata that lets data scientists document the use case, framework, and hyperparameters of their models.
Improvement to the model provenance metadata, including a reference to the model training resource (notebook sessions) by passing training_id into save().
Support for custom metadata which lets data scientists document the context around their models, automatic extraction references to the conda environment used to train the model, the training and validation datasets, and so on.
Automatcal extraction of the model input feature vector and prediction schemas.
Model introspection tests that are run on the model artifact before the model is saved to the model catalog. Model introspection validates the artifact against a series of common issues and errors found with artifacts. These introspection tests are part of the model artifact code template that is included.
Feature Type
Feature type is an additional added module which includes the following functionality:
Support for Explorationary Data Analysis including feature count, feature plot, feature statistics, correlation, and correlation plot.
Support for the feature type manager that provides the tools to manage the handlers used to drive the feature type system.
Support for the feature type validators that are a way of performing data validation and also allow a feature type to be dynamically extended so that the data validation process can be reproducible and shared across projects.
Support for feature type warnings that allow you to automate the process of checking for data quality issues.
May 7, 2021
ADS v2.2.1
ADS v2.2.1 comes with many improvements, and bug fixes.
The improvements include:
Requires Pandas >- 1.2 and Python == 3.7.
Upgraded the scikit-learn dependency to 0.23.2.
Added the ADSTextDataset and the ADS Text Extraction Framework.
Updated the
ADSTunermethod.tune()to allow asynchronous tuning, including the ability to halt, resume, and terminate tuning operations from the main process.Added the ability to load and save
ADSTunertuned trials to Object Storage. The tuning progress can now be saved and loaded in a differentADSTunerobject.Added the ability to update the
ADSTunertuning search space. Hyperparameters can be changed and distribution ranges modified during tuning.Updated plotting functions to plot in real-time while
ADSTunerasynchronous tuning operations proceed.Added methods to report on the remaining budget for running
ADSTunerasynchronous tuner (trials and time-based budgets).Added a method to report the difference between the optimal and current best score for
ADSTunertuning processes with score-based stopping criteria.Added caching for model loading method to avoid model deserialization each time the predict method is called.
Made the list of supported formats in
DatasetFactory.open()more explicit.Moved the
ADSEvaluatorcaption to above the table.Added a warning message in the
get_recommendations()method when no recommendations can be made.Added a parameter in
print_summary()to display the ranking table only.list_appsin theDataFlowclass supports the optional parametercompartment_id.An exception occurs when using SVC or KNN on large datasets in
OracleAutoMLProvider.Speed improvements in correlation calculations.
Improved the name of the y-axis label in
feature_selection_trials().Automatically chooses the y-label based on the
score_metricset intrainif you don’t set it.Increased the default timeout for uploading models to the model catalog.
Improved the module documentation.
Speed improvements in
get_recommendations()on wide datasets.Speed improvements in
DatasetFactory.open().Deprecated the
frackeyword fromDatasetFactory.open().Disabled writing
requirements.txtwhenfunction_artifacts = False.Pretty printing of specific labels in
ADSEvaluator.metrics.Removed the global setting as the only mechanism for choosing the authentication in
OCIClientFactory.Added the ability to have defaults and to provide authentication information while instantiating a Provider Class.
Added a larger time buffer for the
plot_param_importancemethod.Migrated the
DatasetFactoryreading engine from Dask to Pandas.Enabling Pandas to read lists and glob of files.
DatasetFactorynow supports reading from Object Storage usingocifs.The
DatasetFactoryURI pattern now supports namespaces, and follows the HDFS Connector format.The
url()method can generate PARs for Object Storage objects.DatasetFactorynow has caching for Object Storage operations.
The following issues were fixed:
Issue with multipart upload and download in
DatasetFactory.Issues with log level in
OracleAutoMLProvider.Issue with
fill_valuewhen runningget_recommendations().Issue with an invalid training path when saving model provenance.
Issue with errors during model deletion.
Issues with deep copying
ADSData.Evaluation plot KeyError.
Dataset
show_in_notebookissue.Inconsistency in preparing
ADSModelsand generic models.Issue with
force_overwriteinprepare_generic_modelnot being properly triggered.Issue with
OracleAutoMLProviderfailing tovisualize_tuning_trials.Issues with
model_preparetrying to do feature transforms on keras and pytorch models.Erroneous creation of
__pychache__.The
AttributeErrormessage when anApplicationSummaryorRunSummaryobject is being displayed in a notebook.Issues with newer versions of Dask breaking
DatasetFactory.
AutoML
AutoML is upgraded to AutoML v1.0 and the changes include:
Switched to using Pandas Dataframes internally. AutoML now uses Pandas dataframes internally instead of Numpy dataframes, avoiding needless conversions.
Pytorch is now an optional dependency. If Pytorch is installed, AutoML automatically considers multilayer perceptrons in its search. If Pytorch is not found, deep learning models are ignored.
Updated the Pipeline interface to include
train(), which runs all the pipeline stages though doesn’t do the final fitting of the model (fit()api should be used if final fit is needed).Updated the Pipeline interface to include
refit()to allows you to refit the pipeline to an updated dataset without re-running the full pipeline again. We recommend this for advanced users only. For best results, we recommended that you rerun the full pipeline when the dataset changes.AutoML now reports memory usage for each trial as a part of its trials attributes. This information relies on the maximum resident size metric reported by Linux, and can sometimes be unreliable.
holidaysis now an optional dependency. Ifholidaysis installed, AutoML automatically uses it to addholidaysas a feature for engineering datetime columns.Added support for Anomaly Detection and Forecasting tasks (experimental).
Downcast dataset to reduce pipeline training memory consumption.
Set numpy BLAS parallelism to 1 to avoid CPU over subscription.
Created interactive example notebooks for all supported tasks (classification, regression, anomaly detection, and forecasting), see http://automl.oraclecorp.com/.
Other general bug fixes.
MLX
MLX is upgraded to MLX v1.1.1 the changes include:
Upgrading to Python 3.7
Upgrading to support Numpy >= 1.19.4
Upgrading to support Pandas >= 1.1.5
Upgrading to support Scikit-learn >= 0.23.2
Upgrading to support Statsmodel >= 0.12.1
Upgrading to support Dask >= 2.30.0
Upgrading to support Distributed >= 2.30.1
Upgrading to support Xgboost >= 1.2.1
Upgrading to support Category_encoders >= 2.2.2
Upgrading to support Tqdm >= 4.36.1
Fixed imputation issue when columns are all NaN.
Fixed WhatIF internal index-reference issue.
Fixed rare floating point problem in FD/ALE explainers.
Janurary 13, 2021
ADS
A full distribution of this release of ADS is found in the General Machine Learning for CPU and GPU environments. The Classic environments include the previous release of ADS.
A distribution of ADS without AutoML and MLX is found in the remaining environments.
DatasetFactorycan now download files first before opening them in memory using the.download()method.Added support to archive files in creating Data Flow applications and runs.
Support was added for loading Avro format data into ADS.
Changed model serialization to use ONNX by default when possible on supported models.
Added
ADSTuner, which is a framework and model agnostic hyperparmater optimizer, use theadstuner.ipynbnotebook for examples of how to use this feature.Corrected the
up_sample()method inget_recommendations()so that it does not fail when all features are categorical. Up-sampling is possible for datasets containing continuous and categorical features.Resolved issues with serializing
ndarrayobjects into JSON.A table of all of the ADS notebook examples can be found in our service documentation: Oracle Cloud Infrastructure Data Science
Changed set_documentation_mode to false by default.
Added unit-tests related to the dataset helper.
Fixed the _check_object_exists to handle situations where the object storage bucket has more than 1000 objects.
Added option overwrite_script in the create_app() method to allow a user to override a pre-existing file.
Added support for newer fsspec versions.
Added support for the C library Snappy.
Fixed issue with uploading model provenance data due to inconsistency with OCI interface.
Resolved issue with multiple versions of Cryptography being installed when installing fbprophet.
AutoML
AutoML is upgraded to AutoML v0.5.2 and the changes include:
AutoML is now distributed in the General Machine Learning and Data Exploration conda environments.
Support for ONNX. AutoML models can now be serialized using ONNX by calling the
to_onnx()API on the AutoML estimator.Pre-processing has been overhauled to use
sklearnpipelines to allow serialization using ONNX. Numerical, categorical, and text columns are supported for ONNX serialization. Datetime and time series columns are not supported.Torch-based deep learning models, TorchMLPClassifier and TorchMLPRegressor, have been added.
GPU support for XGBoost and torch-based models have been added. This is disabled by default, and can be enabled by passing in
‘gpu_id’: ‘auto’inengine_optsin the constructor. ONNX serialization for GPUs has not been tested.Adaptive sampling’s learning curve has been smoothened. This allows adaptive sampling to converge faster on some datasets.
Improvements to ranking performance in feature selection were added. Feature selection is now much faster on large datasets.
The default execution engine for AutoML has been switched to Dask. You can still use the Python multiprocessing by passing
engine='local', engine_opts={'n_jobs' : -1}toinit()GuassianNB has been enabled in the interface by default.
The
AdaBoostClassifierhas been disabled in the pipeline interface by default. The ONNX converter forAdaBoostshould not be used.The issue
ValueError: Found unknown categories during transformhas been fixed.You can manually specify a hyperparameter search space to AutoML. New parameter added to the pipeline. This allows you to freeze some hyperparmaters or to expose further ones for tuning.
New API: Refit an AutoML pipeline to another dataset. This is primarily used to handle updated training data, where you train the pipeline once, and refit in on newer data.
AutoML no longer closes a user specified Dask cluster.
AutoML properly cleans up any existing futures on the Dask cluster at the end of fit.
MLX
MLX is upgraded to MLX v1.0.16 the changes include:
MLX is now distributed in the General Machine Learning conda environments.
Updated the explanation descriptions to use a base64 representation of the static plots. This obviates the need for creating a
mlx_staticdirectory.Replaced the boolean indexing in slicing Pandas dataFrame with integer indexing. After updating to
Pandas >= 1.1.0the boolean indexing caused some issues. Integer indexing addresses these issues.Fixed MLX related import warnings.
Corrected an issue with ALE when the target values are strings.
Removed the dependency on Paramiko.
Addresses issue with ALE when the target values are not of type
list.
August 11 2020
ADS
Support was added to use Resource principals as an authentication mechanism for ADS.
Support was added to MLX for an additional model explanation diagnostic, Accumulated Local Effects (ALEs).
Support was added to MLX for “What-if” scenarios in model explainability.
Improvements were made to the correlation heatmap calculations in
show_in_notebook().Improvements were made to the model artifact.
Bug Fixes
Data Flow applications inherit the compartment assignment of the client. Runs inherit from applications by default. Compartment OCIDs can also be specied independently at the client, application, and run levels.
The Data Flow log link for logs pulled from an application loaded into the notebook session is fixed.
Progress bars now complete fully (in
ADSModel.prepare()andprepare_generic_model()).BaselineModelis now significantly faster and can be opted out of.
AutoML
No changes.
MLX
MLX upgraded to MLX v1.0.10 the changes include:
Added support to specify the mlx_static root path (used for ALE summary).
Added support for making mlx_static directory hidden (for example, <path>/.mlx_static/).
Fixed issue with the boolean features in ALE.
June 9 2020
ADS
Numerous bug fixes including:
Support for Data Flow applications and runs outside of a notebook session compartment. Support for specific object storage logs and script buckets at the application and run levels.
ADS detects small shapes and gives warnings for AutoML execution.
Removal of triggers in the Oracle Cloud Infrastructure Functions
func.yamlfile.DatasetFactory.open()incorrectly yielding a classification dataset for a continuous target was fixed.LabelEncoderproducing the wrong results for category and object columns was fixed.An untrusted notebook issue when running model explanation visualizations was fixed.
A warning about adaptive sampling requiring at least 1000 datapoints was added.
A dtype cast float to integer into
DatasetFactory.open("csv")was added.An option to specify the bucket of Data Flow logs when you create the application was added.
AutoML
AutoML upgraded to 0.4.2 the changes include:
Reduced parallelization on low compute hardware.
Support for passing in a custom logger object in
automl.init(logger=).Support for
datetimecolumns. AutoML should automatically inferdatetimecolumns based on the Pandas dataframe, and perform feature engineering on them. This can also be forced by using thecol_typesargument inpipeline.fit(). The supported types are:['categorical', 'numerical', 'datetime']
MLX
MLX upgraded to MLX 1.0.7 the changes include:
Updated the feature distributions in the PDP/ICE plots (performance improvement).
All distributions are now shown as PMFs. Categorical features show the category frequency and continuous features are computed using a NumPy histogram (with ‘auto’). They are also separate sub-plots, which are interactive.
Classification PDP: The y-axis for continous features are now auto-scaled (not fixed to 0-1).
1-feature PDP/ICE: The x-axis for continuous features now shows the entire feature distribution, whereas the plot may show a subset depending on the
partial_rangeparameter (for example,partial_range=[0.2, 0.8]computes the PDP between the 20th and 80th percentile. The plot now shows the full distribution on the x-axis, but the line charts are only drawn between the specified percentile ranges).2-feature PDP: The plot x and y axes are now auto-set to match the
partial_rangespecified by the user. This ensures that the heatmap fills the entire plot by default. However, the entire feature distribution can be viewed by zooming out or clicking Autoscale in plotly.Support for plotting scatter plots using WebGL (
show_in_notebook(..., use_webgl=True)) was added.The side-issues that were causing the MLX Visualization Omitted warnings in JupyterLab was fixed.
April 30 2020
Environment Updates
The
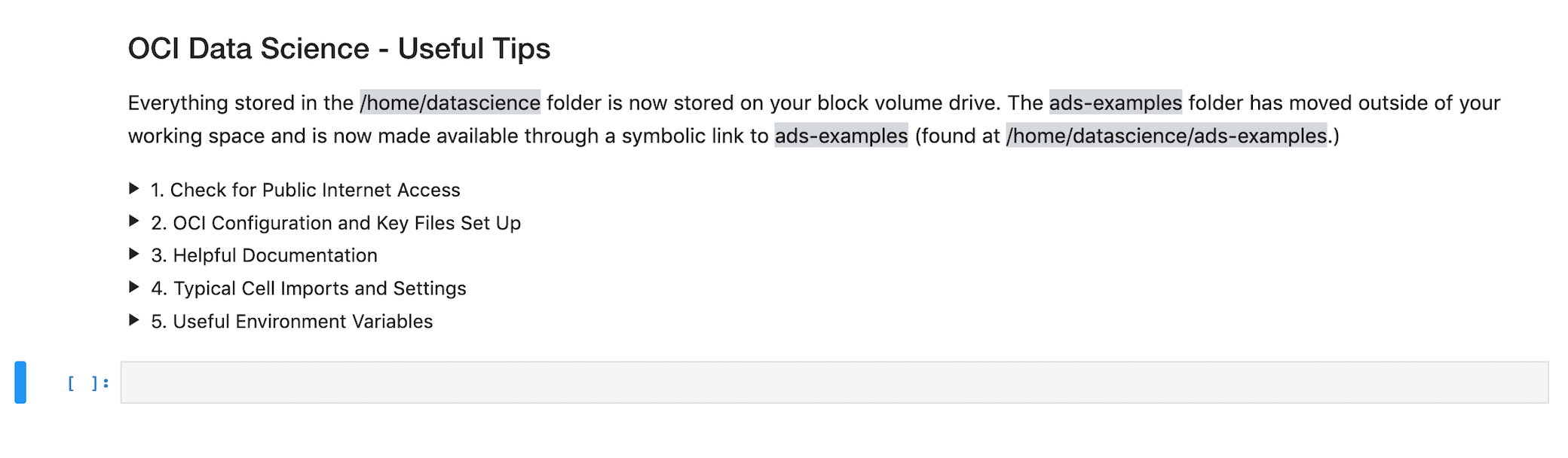
homefolder is now backed by block volume. You can now save all your files to the/home/datasciencefolder, and they persist when you deactivate and activate your sessions. Theblock_storagefolder no longer exists. The Oracle Cloud Infrastructure keys can be saved directly to the~/.ocifolder, and no symbolic links are required.
Note: The ads-examples folder in the home folder is a symbolic link to the /opt/notebooks/ads-examples folder. Any changes made in ads-examples aren’t saved if you deactivate a notebook.
Each new notebook that is launched has a prepopulated accordion style cell containing useful tips.
The following packages were added:
fdk= 0.1.12
pandas-datareader= 0.8.1
py-cpuinfo= 5.0
ADS
ADS integration with the Oracle Cloud Infrastructure Data Flow service provides a more efficient and convenient to launch a Spark application and run Spark jobs
show_in_notebook()has had “head” removed from accordion and is replaced with dataset “warnings”.get_recommendations()is deprecated and replaced withsuggest_recommendations(), which returns a Pandas dataframe with all the recommendations and suggested code to implement each action.A progress indication of Autonomous Data Warehouse reads has been added.
Notebooks
A new notebook is included in the
ads-examplesfolder to demonstrate ADS and DataFlow Integration.A new notebook is included in the
ads-examplesfolder which demonstrates advanced custom scoring functions within AutoML by implementing custom class weights.New version of the notebook example for deployment to Functions and API Gateway: Now using cloud shell.
Significant improvements were made to existing ADS Notebooks.
AutoML
AutoML updated to version 0.4.1 from 0.3.1:
More consistent handling of stratification and random state.
Bug fix for
LightGBMandXGBoostcrashing on AMD shapes was implemented.Unified Proxy Models across all stages of the AutoML Pipeline, ensuring leaderboard rankings are consistent was implemented.
Remove visual option from the interface.
The default tuning metric for both binary and multi-class classification has been changed to
neg_log_loss.Bug fix in AutoML
XGBoost, where the predicted probabilities were sometimes NaN, was implemented.Fixed several corner case issues in Hyperparameter Optimization.
MLX
MLX updated to version 1.0.3 from 1.0.0:
Added support for specifying the ‘average’ parameter in
sklearnmetrics by<metric>_<average>, for examlpleF1_avg.Fixed an issue with the detailed scatter plot visualizations and cutoff feature/axis names.
Fixed an issue with the balanced sampling in the Global Feature Permutation Importance explainer.
Updated the supported scoring metrics in MLX. The
PermutationImportanceexplainer now supports a large number of classification and regression metrics. Also, many of the metrics names were changed.Updated LIME and
PermutationImportanceexplainer descriptions.Fixed an issue where
sklearn.pipelinewasn’t imported.Fixed deprecated
asscalarwarnings.
March 18 2020
Access to ADW performance has been improved significantly
Major improvements made to the performance of the ADW dataset loader. Your data is now loaded much faster, depending on your environment.
Change to DatasetFactory.open() with ADW
DatasetFactory.open() with format='sql' no longer requires the index_col to be specified. This was confusing, since “index” means something very different in databases. Additionally, the table parameter may now be either a table or a sql expression.
ds = DatasetFactory.open(
connection_string,
format = 'sql',
table = """
SELECT *
FROM sh.times
WHERE rownum <= 30
"""
)
No longer automatically starts an H2O cluster
ADS no longer instantiates an H2O cluster on behalf of the user. Instead you need to import h2o on your own and then start your own cluster.
Preloaded Jupyter extensions
JupyterLab now supports these extensions:
BokehPlotlyVegaGeoJSONFASTAVariable InspectorVDOM
Profiling Dask APIs
With support for Bokeh extension, you can now profile Dask operations and visualize profiler output. For more details, see Dask ResourceProfiler.
You can use the ads.common.analyzer.resource_analyze decorator to visualize the CPU and memory utilization of operations.
During execution, it records the following information for each timestep:
Time in seconds since the epoch
Memory usage in MB
% CPU usage
Example:
from ads.common.analyzer import resource_analyze
from ads.dataset.dataset_browser import DatasetBrowser
@resource_analyze
def fetch_data():
sklearn = DatasetBrowser.sklearn()
wine_ds = sklearn.open('wine').set_target("target")
return wine_ds
fetch_data()
The output shows two lines, one for total CPU percentage used by all the workers, and one for total memory used.
Dask Upgrade
Dask is updated to version 2.10.1 with support for Oracle Cloud Infrastructure Object Storage. The 2.10.1 version provides better performance over the older version.