Overview
Training a great model can take a lot of work. Getting that model into production should be quick and easy. ADS has a set of classes that take your model and push it to production with a few quick steps.
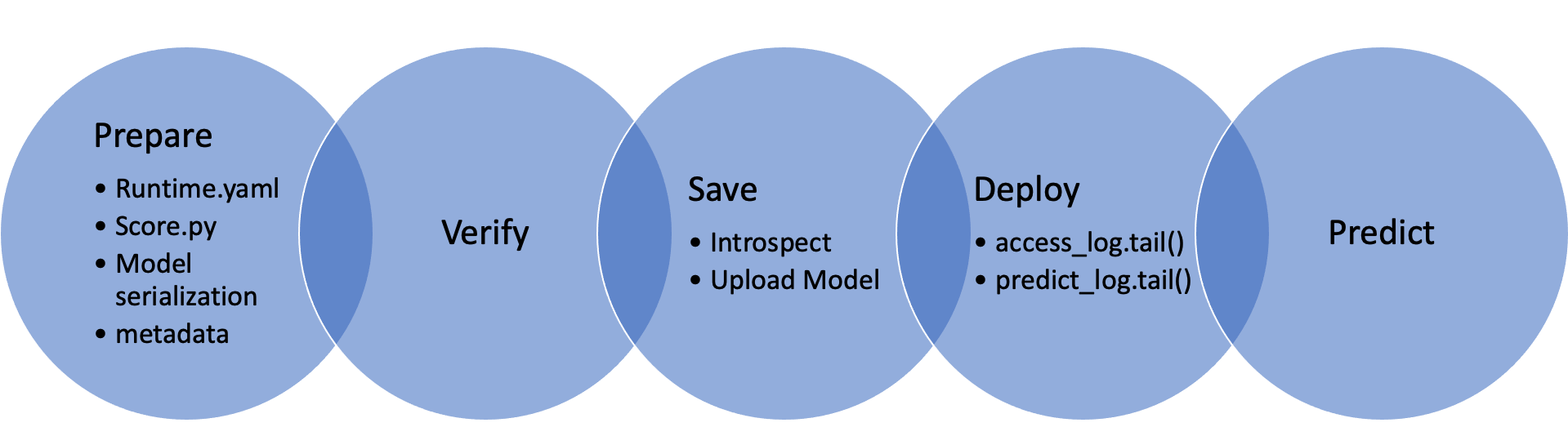
The first step is to create a model serialization object. This object wraps your model and has a number of methods to assist in deploying it. There are different model classes for different model classes. For example, if you have a PyTorch model you would use the PyTorchModel class. If you have a TensorFlow model you would use the TensorFlowModel class. ADS has model serialization for many different model classes. However, it is not feasible to have a model serialization class for all model types. Therefore, the GenericModel can be used for any class that has a .predict() method.
After creating the model serialization object, the next step is to use the .prepare() method to create the model artifacts. The score.py file is created and it is customized to your model class. You may still need to modify it for your specific use case but this is generally not required. The .prepare() method also can be used to store metadata about the model, code used to create the model, input and output schema, and much more.
If you make changes to the score.py file, call the .verify() method to confirm that the load_model() and predict() functions in this file are working. This speeds up your debugging as you do not need to deploy a model to test it.
The .save() method is then used to store the model in the model catalog. A call to the .deploy() method creates a load balancer and the instances needed to have an HTTPS access point to perform inference on the model. Using the .predict() method, you can send data to the model deployment endpoint and it will return the predictions.