Load Registered Model
Load and recreate framework specific wrapper objects using the ocid value of your model.
The loaded artifact can be used for running inference in local environment. You can update the artifact files to change your score.py or model and then register as a new model. See here to learn how to change score.py
Here is an example for loading back a LightGBM model that was previously registered. See API documentation for more details.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_model_catalog(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
)
You can print a model to see some details about it.
print(lgbm_model)
algorithm: null
artifact_dir: lgbm-download-test:
- - model.pkl
- output_schema.json
- runtime.yaml
- score.py
- input_schema.json
framework: null
model_deployment_id: null
model_id: ocid1.datasciencemodel.oc1.iad.xxx
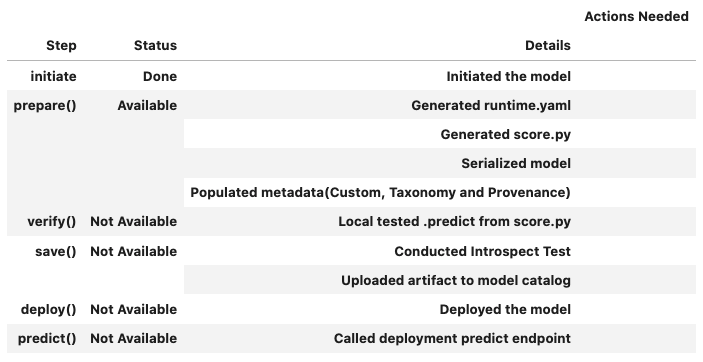
You can call the .summary_status() method after a model serialization instance such as AutoMLModel, GenericModel, SklearnModel, TensorFlowModel, or PyTorchModel is created. The .summary_status() method returns a Pandas dataframe that guides you through the entire workflow. It shows which methods are available to call and which ones aren’t. Plus it outlines what each method does. If extra actions are required, it also shows those actions.
The following image displays an example summary status table created after a user initiates a model instance. The table’s Step column displays a Status of Done for the initiate step. And the Details column explains what the initiate step did such as generating a score.py file. The Step column also displays the prepare(), verify(), save(), deploy(), and predict() methods for the model. The Status column displays which method is available next. After the initiate step, the prepare() method is available. The next step is to call the prepare() method.
New in version 2.6.9.
Alternatively the .from_id() method can be used to load a model. In future releases, the .from_model_catalog() method will be deprecated and replaced with the from_id(). See API documentation for more details.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_id(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
bucket_uri=<oci://<bucket_name>@<namespace>/prefix/>,
force_overwrite=True,
remove_existing_artifact=True,
)
Load Deployed Model
Load and recreate framework specific wrapper objects using the ocid value of your OCI Model Deployment instance.
The loaded artifact can be used for running inference in local environment. You can update the artifact files to change your score.py or model and then register as a new model. See here to learn how to change score.py
Here is an example for loading back a LightGBM model that was previously deployed. See API doc for more infomation.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_model_deployment(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
)
You can print a model to see some details about it.
print(lgbm_model)
algorithm: null
artifact_dir: lgbm-download-test:
- - model.pkl
- output_schema.json
- runtime.yaml
- score.py
- input_schema.json
framework: null
model_deployment_id: null
model_id: ocid1.datasciencemodel.oc1.iad.xxx
New in version 2.6.9.
Alternatively the .from_id() method can be used to load a model from the Model Deployment. In future releases, the .from_model_deployment() method will be deprecated and replaced with the from_id(). See API documentation for more details.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_id(
"ocid1.datasciencemodeldeployment.oc1.xxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
bucket_uri=<oci://<bucket_name>@<namespace>/prefix/>,
force_overwrite=True,
remove_existing_artifact=True,
)
Load Model From Object Storage
Load and recreate framework specific wrapper objects from the existing model artifact archive.
The loaded artifact can be used for running inference in local environment. You can update the artifact files to change your score.py or model and then register as a new model. See here to learn how to change score.py
Here is an example for loading back a LightGBM model that was previously saved to the Object Storage. See API doc for more infomation.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_model_artifact(
<oci://<bucket_name>@<namespace>/prefix/lgbm_model_artifact.zip>,
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
force_overwrite=True
)
A model loaded from an artifact archive can be registered and deployed.
You can print a model to see some details about it.
print(lgbm_model)
algorithm: null
artifact_dir: lgbm-download-test:
- - model.pkl
- output_schema.json
- runtime.yaml
- score.py
- input_schema.json
framework: null
model_deployment_id: null
model_id: ocid1.datasciencemodel.oc1.iad.xxx
Large Model Artifacts
New in version 2.6.4.
Large models are models with artifacts between 2 and 6 GB. You must first download large models from the model catalog to an Object Storage bucket, and then transfer them to local storage. For model artifacts that are less than 2 GB, you can use the same approach, or download them directly to local storage. An Object Storage bucket is required with Data Science service access granted to that bucket.
If you don’t have an Object Storage bucket, create one using the OCI SDK or the Console. Create an Object Storage bucket. Make a note of the namespace, compartment, and bucket name. Configure the following policies to allow the Data Science service to read and write the model artifact to the Object Storage bucket in your tenancy. An administrator must configure these policies in IAM in the Console.
Allow service datascience to manage object-family in compartment <compartment> where ALL {target.bucket.name='<bucket_name>'}
Allow service objectstorage to manage object-family in compartment <compartment> where ALL {target.bucket.name='<bucket_name>'}
The following example loads a model using the large model artifact approach. The bucket_uri has the following syntax: oci://<bucket_name>@<namespace>/<path>/ See API documentation for more details.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_model_catalog(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
bucket_uri=<oci://<bucket_name>@<namespace>/prefix/>,
force_overwrite=True,
remove_existing_artifact=True,
)
Here is an example for loading back a LightGBM model with large artifact from Model Deployment. See API doc for more infomation.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_model_deployment(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
bucket_uri=<oci://<bucket_name>@<namespace>/prefix/>,
force_overwrite=True,
remove_existing_artifact=True,
)
New in version 2.6.9.
Alternatively the .from_id() method can be used to load registered or deployed model. In future releases, the .from_model_catalog() and .from_model_deployment() methods will be deprecated and replaced with the from_id(). See API documentation for more details.
from ads.model import LightGBMModel
lgbm_model = LightGBMModel.from_id(
"ocid1.datasciencemodel.oc1.xxx.xxxxx",
model_file_name="model.joblib",
artifact_dir="lgbm-download-test",
bucket_uri=<oci://<bucket_name>@<namespace>/prefix/>,
force_overwrite=True,
remove_existing_artifact=True,
)