Register, Manage, and Deploy Models¶
You could register your model with OCI Data Science service through ADS. Alternatively, the Oracle Cloud Infrastructure (OCI) Console can be used by going to the Data Science projects page, selecting a project, then click Models. The models page shows the model artifacts that are in the model catalog for a given project.
After a model and its artifacts are registered, they become available for other data scientists if they have the correct permissions.
Data scientists can:
List, read, download, and load models from the catalog to their own notebook sessions.
Download the model artifact from the catalog, and run the model on their laptop or some other machine.
Deploy the model artifact as a model deployment.
Document the model use case and algorithm using taxonomy metadata.
Add custom metadata that describes the model.
Document the model provenance including the resources and tags used to create the model (notebook session), and the code used in training.
Document the input data schema, and the returned inference schema.
Run introspection tests on the model artifact to ensure that common model artifact errors are flagged. Thus, they can be remediated before the model is saved to the catalog.
The ADS SDK automatically captures some of the metadata for you. It captures provenance, taxonomy, and some custom metadata.
Workflow¶
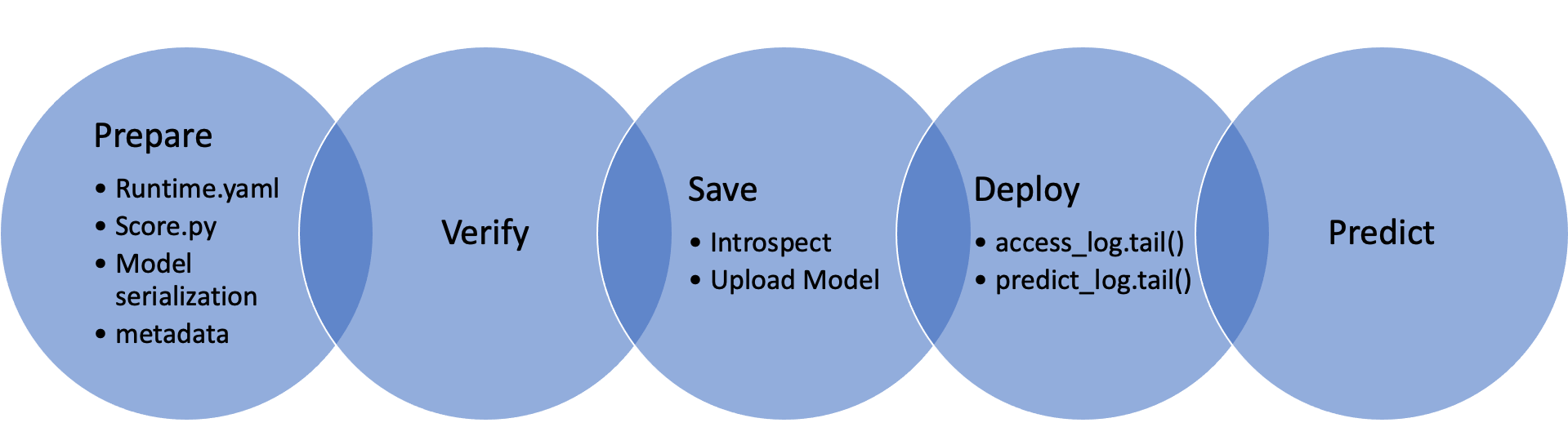
ADS has a set of framework specific classes that take your model and push it to production with a few quick steps.
The first step is to create a model serialization object. This object wraps your model and has a number of methods to assist in deploying it. There are different model classes for different model classes. For example, if you have a PyTorch model you would use the PyTorchModel class. If you have a TensorFlow model you would use the TensorFlowModel class. ADS has model serialization for many different model classes. However, it is not feasible to have a model serialization class for all model types. Therefore, the GenericModel can be used for any class that has a .predict() method.
After creating the model serialization object, the next step is to use the .prepare() method to create the model artifacts. The score.py file is created and it is customized to your model class. You may still need to modify it for your specific use case but this is generally not required. The .prepare() method also can be used to store metadata about the model, code used to create the model, input and output schema, and much more.
If you make changes to the score.py file, call the .verify() method to confirm that the load_model() and predict() functions in this file are working. This speeds up your debugging as you do not need to deploy a model to test it.
The .save() method is then used to store the model in the model catalog. A call to the .deploy() method creates a load balancer and the instances needed to have an HTTPS access point to perform inference on the model. Using the .predict() method, you can send data to the model deployment endpoint and it will return the predictions.
Warning
Treat /predict request bodies as untrusted input. Use JSON-compatible
serializers for request data whenever possible. Cloudpickle remains
supported for trusted model artifact save/load workflows, but should not be
used as a request payload format. ADS-generated scoring artifacts do not
deserialize cloudpickle request payloads. If you provide a custom
score.py, you are responsible for validating request input and avoiding
unsafe deserialization. ADS-generated model artifact archives include
model_artifact_manifest.json. When the manifest is present, ADS validates
the complete file list and SHA-256 hashes during artifact extraction, and
generated loaders verify the main model file hash when supported. Older
artifacts without a manifest remain loadable for compatibility.