Plugin#
One of the most powerful features of ADSString is that you can expand and customize it. The .plugin_register() method allows you to add properties to the ADSString class. These plugins can be provided by third-party providers or developed by you. This section demonstrates how to connect the to the OCI Language service, and how to create a custom plugin.
Custom Plugin#
You can bind additional properties to ADSString using custom plugins. This allows you to create custom text processing extensions. A plugin has access to the self.string property in ADSString class. You can define functions that perform a transformation on the text in the object. All functions defined in a plugin are bound to ADSString and accessible across all objects of that class.
Assume that your text is "I purchased the gift on this card 4532640527811543 and the dinner on 340984902710890" and you want to know what credit cards were used. The .credit_card property returns the entire credit card number. However, for privacy reasons you don’t what the entire credit card number, but the last four digits.
To solve this problem, you can create the class CreditCardLast4 and use the self.string property in ADSString to access the text associated with the object. It then calls the .credit_card method to get the credit card numbers. Then it parses this to return the last four characters in each credit card.
The first step is to define the class that you want to bind to ADSString. Use the @property decorator and define a property function. This function only takes self. The self.string is accessible with the text that is defined for a given object. The property returns a list.
class CreditCardLast4:
@property
def credit_card_last_4(self):
return [x[len(x)-4:len(x)] for x in ADSString(self.string).credit_card]
After the class is defined, it must be registered with ADSString using the .register_plugin() method.
ADSString.plugin_register(CreditCardLast4)
Take the text and make it an ADSString object, and call the .credit_card_last_4 property to obtain the last four digits of the credit cards that were used.
creditcard_numbers = "I purchased the gift on this card 4532640527811543 and the dinner on 340984902710890"
s = ADSString(creditcard_numbers)
s.credit_card_last_4
['1543', '0890']
OCI Language Services#
The OCI Language service provides pretrained models that provide sophisticated text analysis at scale.
The Language service contains these pretrained language processing capabilities:
Aspect-Based Sentiment Analysis: Identifies aspects from the given text and classifies each into positive, negative, or neutral polarity.Key Phrase Extraction: Extracts an important set of phrases from a block of text.Language Detection: Detects languages based on the given text, and includes a confidence score.Named Entity Recognition: Identifies common entities, people, places, locations, email, and so on.Text Classification: Identifies the document category and subcategory that the text belongs to.
Those are accessible in ADS using the OCILanguage plugin.
ADSString.plugin_register(OCILanguage)
Aspect-Based Sentiment Analysis#
Aspect-based sentiment analysis can be used to gauge the mood or the tone of the text.
The aspect-based sentiment analysis (ABSA) supports fine-grained sentiment analysis by extracting the individual aspects in the input document. For example, a restaurant review “The driver was really friendly, but the taxi was falling apart.” contains positive sentiment toward the taxi driver aspect. Also, it has a strong negative sentiment toward the service mechanical aspect of the taxi. Classifying the overall sentiment as negative would neglect the fact that the taxi driver was nice.
ABSA classifies each of the aspects into one of the three polarity classes, positive, negative, mixed, and neutral. With the predicted sentiment for each aspect. It also provides a confidence score for each of the classes and their corresponding offsets in the input. The range of the confidence score for each class is between 0 and 1, and the cumulative scores of all the three classes sum to 1.
In the next example, the sample sentence is analyzed. The two aspects, taxi cab and driver, have their sentiments determined. It defines the location of the aspect by giving its offset position in the text, and the length of the aspect in characters. It also gives the text that defines the aspect along with the sentiment scores and which sentiment is dominant.
t = ADSString("The driver was really friendly, but the taxi was falling apart.")
t.absa

Key Phrase Extraction#
Key phrase (KP) extraction is the process of extracting the words with the most relevance, and expressions from the input text. It helps summarize the content and recognizes the main topics. The KP extraction finds insights related to the main points of the text. It understands the unstructured input text, and returns keywords and KPs. The KPs consist of subjects and objects that are being talked about in the document. Any modifiers, like adjectives associated with these subjects and objects, are also included in the output. Confidence scores for each key phrase that signify how confident the algorithm is that the identified phrase is a KP. Confidence scores are a value from 0 to 1.
The following example determines the key phrases and the importance of these phrases in the text (which is the value of test_text):
Lawrence Joseph Ellison (born August 17, 1944) is an American business magnate,
investor, and philanthropist who is a co-founder, the executive chairman and
chief technology officer (CTO) of Oracle Corporation. As of October 2019, he was
listed by Forbes magazine as the fourth-wealthiest person in the United States
and as the sixth-wealthiest in the world, with a fortune of $69.1 billion,
increased from $54.5 billion in 2018.[4] He is also the owner of the 41st
largest island in the United States, Lanai in the Hawaiian Islands with a
population of just over 3000.
s = ADSString(test_text)
s.key_phrase

Language Detection#
The language detection tool identifies which natural language the input text is in. If the document contains more than one language, the results may not be what you expect. Language detection can help make customer support interactions more personable and quicker. Customer service chatbots can interact with customers based on the language of their input text and respond accordingly. If a customer needs help with a product, the chatbot server can field the corresponding language product manual, or transfer it to a call center for the specific language.
The following is a list of some of the supported languages:
Afrikaans |
Albanian |
Arabic |
Armenian |
Azerbaijani |
Basque |
Belarusian |
Bengali |
Bosnian |
Bulgarian |
Burmese |
Cantonese |
Catalan |
Cebuano |
Chinese |
Croatian |
Czech |
Danish |
Dutch |
Eastern Punjabi |
Egyptian Arabic |
English |
Esperanto |
Estonian |
Finnish |
French |
Georgian |
German |
Greek |
Hebrew |
Hindi |
Hungarian |
Icelandic |
Indonesian |
Irish |
Italian |
Japanese |
Javanese |
Kannada |
Kazakh |
Korean |
Kurdish (Sorani) |
Latin |
Latvian |
Lithuanian |
Macedonian |
Malay |
Malayalam |
Marathi |
Minangkabau |
Nepali |
Norwegian (Bokmal) |
Norwegian (Nynorsk) |
Persian |
Polish |
Portuguese |
Romanian |
Russian |
Serbian |
Serbo-Croatian |
Slovak |
Slovene |
Spanish |
Swahili |
Swedish |
Tagalog |
Tamil |
Telugu |
Thai |
Turkish |
Ukrainian |
Urdu |
Uzbek |
Vietnamese |
Welsh |
The next example determines the language of the text, the ISO 639-1 language code, and a probability score.
s.language_dominant

Named Entity Recognition#
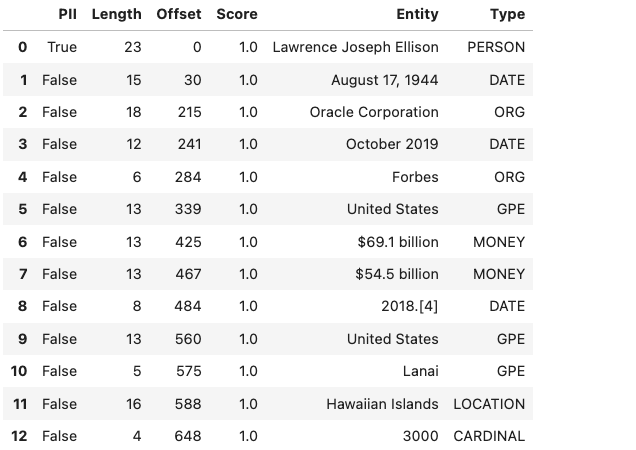
Named entity recognition (NER) detects named entities in text. The NER model uses NLP, which uses machine learning to find predefined named entities. This model also provides a confidence score for each entity and is a value from 0 to 1. The returned data is the text of the entity, its position in the document, and its length. It also identifies the type of entity, a probability score that it is an entity of the stated type.
The following are the supported entity types:
DATE: Absolute or relative dates, periods, and date range.EMAIL: Email address.EVENT: Named hurricanes, sports events, and so on.FAC: Facilities; Buildings, airports, highways, bridges, and so on.GPE: Geopolitical entity; Countries, cities, and states.IPADDRESS: IP address according to IPv4 and IPv6 standards.LANGUAGE: Any named language.LOCATION: Non-GPE locations, mountain ranges, and bodies of water.MONEY: Monetary values, including the unit.NORP: Nationalities, religious, and political groups.ORG: Organization; Companies, agencies, institutions, and so on.PERCENT: Percentage.PERSON: People, including fictional characters.PHONE_NUMBER: Supported phone numbers.(“GB”) - United Kingdom
(“AU”) - Australia
(“NZ”) - New Zealand
(“SG”) - Singapore
(“IN”) - India
(“US”) - United States
PRODUCT: Vehicles, tools, foods, and so on (not services).QUANTITY: Measurements, as weight or distance.TIME: Anything less than 24 hours (time, duration, and so on).URL: URL
The following example lists the named entities:
s.ner
The output gives the named entity, its location, and offset position in the text. It also gives a probability and score that this text is actually a named entity along with the type.
Text Classification#
Text classification analyses the text and identifies categories for the content with a confidence score. Text classification uses NLP techniques to find insights from textual data. It returns a category from a set of predefined categories. This text classification uses NLP and relies on the main objective lies on zero-shot learning. It classifies text with no or minimal data to train. The content of a collection of documents is analyzed to determine common themes.
The next example classifies the text and gives a probability score that the text is in that category.
s.text_classification
