Introduction to AutoMLModel
Overview:
The AutoMLModel class in ADS is designed to allow you to rapidly get
an AutoML model into production. The .prepare() method creates the
model artifacts that are needed to deploy a functioning model without
you having to configure it or write code. However, you can
customize the required score.py file.
Simulate a call to a deployed model with the .verify() method. This method calls the
load_model() and predict() functions in the score.py file.
Using .verify() allows you to debug your score.py file without
having to deploy a model. The .save() method deploys your
AutoMLModel and the model artifacts to the model catalog. The
.deploy() method deploys the model to a REST endpoint for you.
These simple steps take your trained AutoML model and deploy it into
production with just a few lines of code.
Creating an Oracle Labs AutoML Model
Create an OracleAutoMLProvider object tells the AutoML object how to
train the models by creating an Oracle Labs AutoML model.
import logging
import warnings
from ads.automl.driver import AutoML
from ads.automl.provider import OracleAutoMLProvider
from ads.dataset.dataset_browser import DatasetBrowser
ds = DatasetBrowser.sklearn().open("wine").set_target("target")
train, test = ds.train_test_split(test_size=0.1, random_state = 42)
ml_engine = OracleAutoMLProvider(n_jobs=-1, loglevel=logging.ERROR)
oracle_automl = AutoML(train, provider=ml_engine)
model, baseline = oracle_automl.train(model_list=['LogisticRegression', 'DecisionTreeClassifier'],
random_state = 42, time_budget = 500)
Initialize
You instantiate an AutoMLModel() object with an AutoML model. Each instance accepts the following parameters:
estimator: (Callable): Trained AutoML model.artifact_dir: str: Artifact directory to store the files needed for deployment.properties: (ModelProperties, optional): Defaults toNone. TheModelPropertiesobject required to save and deploy a model.auth: (Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. If you need to override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal()to create an appropriate authentication signer and any**kwargsthat are required to instantiate theIdentityClientobject.
The properties instance of ModelProperties has the following predefined fields:
compartment_id: strdeployment_access_log_id: strdeployment_bandwidth_mbps: intdeployment_instance_count: intdeployment_instance_shape: strdeployment_log_group_id: strdeployment_predict_log_id: strinference_conda_env: strinference_python_version: strproject_id: strtraining_conda_env: strtraining_id: strtraining_python_version: strtraining_resource_id: strtraining_script_path: str
By default, properties is populated from the appropriate environment variables if it’s
not specified. For example, in a notebook session, the environment variables
for project id and compartment id are preset and stored in PROJECT_OCID and
NB_SESSION_COMPARTMENT_OCID by default. So properties populates these variables
from the environment variables and uses the values in methods such as .save() and .deploy().
However, you can always explicitly pass the variables into functions to overwrite
the values. For the fields that properties has, it records the values that you pass into the functions.
For example, when you pass inference_conda_env into the .prepare() method, then properties records this value.
You can export it using the .to_yaml() method and reload it into a different machine using the .from_yaml() method. This allows you to reuse the properties in different places.
Summary Status
AutoMLModel.summary_status()
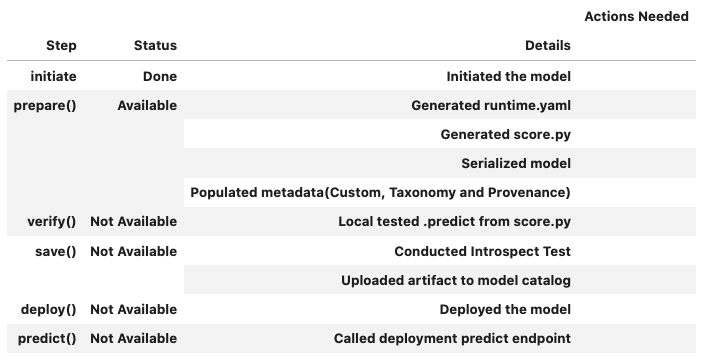
You can call the summary_status() function any time after the AutoMLModel instance is created. It returns a Pandas dataframe that guides you through the entire workflow. It shows which methods are available to call, which ones aren’t. Plus it outlines what a method does. If extra actions are required, it also shows those.
An example of a summary status table looks similar to the following. The step column shows all the methods. It shows that the initial step is completed, the Details column explains what the initiating step did. It also indicates that the .prepare() method is now available. The next step is to call the .prepare() method.
Prepare
The prepare step is performed by the .prepare() method of the. It creates a number of
customized files that are used to run the model once it is deployed. These include:
input_schema.json: A JSON file that defines the nature of the feature data. It includes information about the features. This includes metadata such as the data type, name, constraints, summary statistics, feature type, and more.model.pkl: This is the default filename of the serialized model. It can be changed with themodel_file_nameattribute. By default, the model is stored in a pickle file. Note that onnx serialization method is not supported.output_schema.json: A JSON file that defines the nature of the dependent variable. This includes metadata such as the data type, name, constraints, summary statistics, feature type, and more.runtime.yaml: This file contains information that is needed to set up the runtime environment on the deployment server. It has information about which conda environment was used to train the model, and what environment should be used to deploy the model. The file also specifies what version of Python should be used.score.py: This script contains theload_modelandpredictfunctions. Theload_modelfunction understands the format the model file was saved in and loads it into memory. Thepredictfunction is used to make inferences in a deployed model. There are also hooks that allow you to perform operations before and after inference. You are able to modify this script to fit your specific needs.
To create the model artifacts, you use the .prepare() method. There
are a number of parameters that allow you to store model provenance
information.
AutoMLModel.prepare()
The AutoMLModel.prepare() method prepares and saves the score.py file, serializes the
model and runtime.yaml file using the following parameters:
X_sample: Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]: Defaults toNone. A sample of the input data. It is used to generate the input schema.force_overwrite: (bool, optional): Defaults toFalse. IfTrue, it will overwrite existing files.ignore_pending_changes: bool: Defaults toFalse. IfFalse, it will ignore the pending changes in Git.inference_conda_env: (str, optional): Defaults toNone. Can be either slug or the Object Storage path of the conda environment. You can only pass in slugs if the conda environment is a service environment.inference_python_version: (str, optional): Defaults toNone. Python version to use in deployment.max_col_num: (int, optional): Defaults toutils.DATA_SCHEMA_MAX_COL_NUM. Do not generate the input schema if the input has more than this number of features.model_file_name: (str): Name of the serialized model.namespace: (str, optional): Namespace of region. This is used for identifying which region the service environment is from when you pass a slug toinference_conda_envandtraining_conda_env.training_conda_env: (str, optional): Defaults to None. Can be either slug or object storage path of the conda environment. You can only pass in slugs if the conda environment is a service environment.training_id: (str, optional): Defaults to value from environment variables. The training OCID for the model. Can be a notebook session or job OCID.training_python_version: (str, optional): Defaults to None. Python version used during training.training_script_path: str: Defaults toNone. The training script path.use_case_type: str: The use case type of the model. Use it with theUserCaseTypeclass or string provided inUseCaseType. For example,use_case_type=UseCaseType.BINARY_CLASSIFICATIONoruse_case_type="binary_classification", see theUseCaseTypeclass to see all supported types.y_sample: Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]: Defaults to None. A sample of output data is used to generate the output schema.**kwargs:impute_values: (dict, optional): The dictionary where the key is the column index (or names is accepted for Pandas dataframe), and the value is the imputed value for the corresponding column.
Verify
If you modify the score.py file that is part of the model artifacts, use the verify step to test those changes. You can do this without having to deploy the model. This allows you to debug your code without having to save the model to the model catalog and then deploy it. The .verify() method takes a set of test parameters and performs the prediction by calling the predict function in score.py. It also runs the load_model function to load the model.
AutoMLModel.verify()
AutoMLModel.verify() method tests whether the .predict() API works in the local environment and it takes the following parameter:
data (Union[dict, str]): The data is used to test if deployment works in the local environment.
Save
After you are satisfied with the performance of the model and have
verified that the score.py file is working, you can save the model
to the model catalog. You do this with the .save() method on a
AutoMLModel object. This bundles up the model artifacts that you have
created and stores them in the model catalog. It returns the model OCID.
AutoMLModel.save()
The AutoMLModel.save() method saves the model files to the model artifact. It takes the following parameters:
defined_tags: (Dict(str, dict(str, object)), optional): Defaults toNone. Defined tags for the model.description: (str, optional): Defaults toNone. The description of the model.display_name: (str, optional): Defaults toNone. The name of the model.freeform_tags: Dict(str, str): Defaults toNone. Free form tags for the model.ignore_introspection: (bool, optional): Defaults toNone. Determine whether to ignore the result of model introspection or not. If set toTrue, thensave()ignores all model introspection errors. ***kwargs:compartment_id : (str, optional): Compartment OCID. If not specified, the value is taken either from the environment variables or model properties.project_id: (str, optional): Project OCID. If not specified, the value is taken either from the environment variables or model properties.timeout: (int, optional): Defaults to 10 seconds. The connection timeout in seconds for the client.
Deploy
With the model in the model catalog, you can use the .deploy() method of an AutoMLModel object to deploy the model. This method allows you to specify the attributes of the deployment such as the display name, description, instance type, number of instances, the maximum bandwidth of the router, and the logging groups. The .deploy() method returns a ModelDeployment object.
AutoMLModel.deploy()
The AutoMLModel.deploy() method is used to deploy a model. The model must be saved to the model catalog first. The API takes the following parameters:
deployment_access_log_id: (str, optional): Defaults toNone. The access log OCID for the access logs, see logging.deployment_bandwidth_mbps: (int, optional): Defaults to 10. The bandwidth limit on the load balancer in Mbps.deployment_instance_count: (int, optional): Defaults to 1. The number of instances used for deployment.deployment_instance_shape: (str, optional): Defaults to VM.Standard2.1. The shape of the instance used for deployment.deployment_log_group_id: (str, optional): Defaults toNone. The OCI logging group id. The access log and predict log share the same log group.deployment_predict_log_id: (str, optional): Defaults toNone. The predict log OCID for the predict logs, see logging.description: (str, optional): Defaults toNone. The description of the model.display_name: (str, optional): Defaults toNone. The name of the model.wait_for_completion : (bool, optional): Defaults toTrue. Flag set to wait for the deployment to complete before proceeding.**kwargs:compartment_id : (str, optional): Compartment OCID. If not specified, then the value is taken from the environment variables.max_wait_time : (int, optional): Defaults to 1200 seconds. The maximum amount of time to wait in seconds. Negative implies an infinite wait time.poll_interval : (int, optional): Defaults to 60 seconds. Poll interval in seconds.project_id: (str, optional): Project OCID. If not specified, then the value is taken from the environment variables.
You can pass in deployment_log_group_id, deployment_access_log_id and deployment_predict_log_id to enable the logging. Please refer to this logging example for an example on logging. To create a log group, you can reference Logging session.
Predict
After the deployment is active, you can call the .predict() method on the AutoMLModel object to send a request to the deployed endpoint to compute the inference values based on the data in the .predict() method.
AutoMLModel.predict()
The AutoMLModel.predict() method returns a prediction of input data that is run against the model deployment endpoint and takes the following parameter:
data: Any: JSON serializable data for the prediction for ONNX models. For a local serialization method, the data can be the data types that each framework support.
Delete a Deployment
Use the .delete_deployment() method on the AutoMLModel object to do delete a deployment. You must delete the model deployment before the model can be deleted from the model catalog.
AutoMLModel.delete_deployment()
The AutoMLModel.delete_deployment() method is used to delete the current
deployment and takes the following parameter:
wait_for_completion: (bool, optional): Defaults toFalse. IfTrue, the process will block until the model deployment has been terminated.
Each time you call the .deploy() method, it creates a new deployment. Only the most recent deployment is attached to the AutoMLModel object.
from_model_artifact
.from_model_artifact() allows to load a model from a folder, zip or tar achive files, where the folder/zip/tar files should contain the files such as runtime.yaml, score.py, the serialized model file needed for deployments. It takes the following parameters:
uri: str: The folder path, ZIP file path, or TAR file path. It could contain a seriliazed model(required) as well as any files needed for deployment including: serialized model, runtime.yaml, score.py and etc. The content of the folder will be copied to theartifact_dirfolder.model_file_name: str: The serialized model file name.artifact_dir: str: The artifact directory to store the files needed for deployment.auth: (Dict, optional): Defaults to None. The default authetication is set usingads.set_authAPI. If you need to override the default, use the ads.common.auth.api_keys or ads.common.auth.resource_principal to create appropriate authentication signer and kwargs required to instantiate IdentityClient object.force_overwrite: (bool, optional): Defaults to False. Whether to overwrite existing files or not.properties: (ModelProperties, optional): Defaults to None. ModelProperties object required to save and deploy model.
After this is called, you can call .verify(), .save() and etc.
from_model_catalog
from_model_catalog allows to load a remote model from model catalog using a model id , which should contain the files such as runtime.yaml, score.py, the serialized model file needed for deployments. It takes the following parameters:
model_id: str. The model OCID.model_file_name: (str). The name of the serialized model.artifact_dir: str. The artifact directory to store the files needed for deployment. Will be created if not exists.auth: (Dict, optional). Defaults to None. The default authetication is set usingads.set_authAPI. If you need to override the default, use theads.common.auth.api_keysorads.common.auth.resource_principalto create appropriate authentication signer and kwargs required to instantiate IdentityClient object.force_overwrite: (bool, optional). Defaults to False. Whether to overwrite existing files or not.properties: (ModelProperties, optional). Defaults to None. ModelProperties object required to save and deploy model.
kwargs:
compartment_id : (str, optional). Compartment OCID. If not specified, the value will be taken from the environment variables.timeout : (int, optional). Defaults to 10 seconds. The connection timeout in seconds for the client.
Example
AutoML pkl Serialization
import logging
import tempfile
import warnings
from ads.automl.driver import AutoML
from ads.automl.provider import OracleAutoMLProvider
from ads.common.model_metadata import UseCaseType
from ads.dataset.dataset_browser import DatasetBrowser
from ads.model.framework.automl_model import AutoMLModel
ds = DatasetBrowser.sklearn().open("wine").set_target("target")
train, test = ds.train_test_split(test_size=0.1, random_state = 42)
ml_engine = OracleAutoMLProvider(n_jobs=-1, loglevel=logging.ERROR)
oracle_automl = AutoML(train, provider=ml_engine)
model, baseline = oracle_automl.train(
model_list=['LogisticRegression', 'DecisionTreeClassifier'],
random_state = 42,
time_budget = 500
)
artifact_dir = tempfile.mkdtemp()
automl_model = AutoMLModel(estimator=model, artifact_dir=artifact_dir)
automl_model.prepare(inference_conda_env="generalml_p37_cpu_v1",
training_conda_env="generalml_p37_cpu_v1",
use_case_type=UseCaseType.BINARY_CLASSIFICATION,
X_sample=test.X,
force_overwrite=True,
training_id=None)
automl_model.verify(test.X.iloc[:10])
model_id = automl_model.save(display_name='Demo AutoMLModel model')
deploy = automl_model.deploy(display_name='Demo AutoMLModel deployment')
automl_model.predict(test.X.iloc[:10])
automl_model.delete_deployment()
Loading Model From a Zip Archive
model = AutoMLModel.from_model_artifact("/folder_to_your/artifact.zip",
model_file_name="your_model_file_name",
artifact_dir=tempfile.mkdtemp())
model.verify(your_data)
Loading Model From Model Catalog
model = AutoMLModel.from_model_catalog(model_id="ocid1.datasciencemodel.oc1.iad.amaaaa....",
model_file_name="your_model_file_name",
artifact_dir=tempfile.mkdtemp())
model.verify(your_data)