How To Run¶
It’s time to run operators in your chosen backend.
Prerequisites
Before we start, let’s ensure you have everything you need for easy starting. If you haven’t already, install the accompanying CLI tool, detailed installation instructions can be found in the links below.
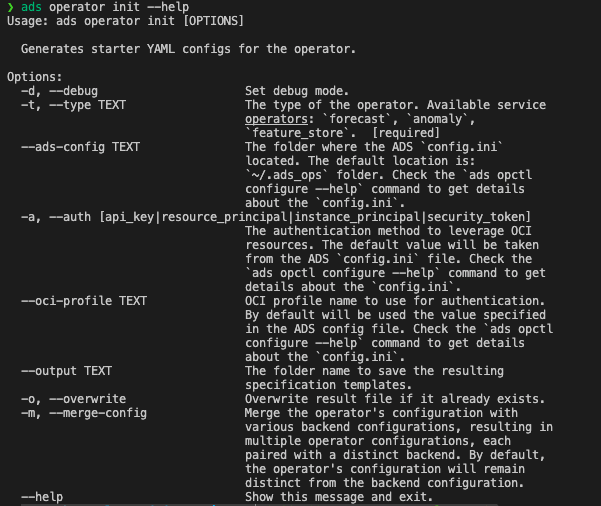
The first step is to generate starter kit configurations that simplify the execution of the operator across different backends. This can be done easily using the following command:
ads operator init --help
Important
If the
--merge-configflag is set totrue, the<operator-type>.yamlfile will be merged with the backend configuration which contains pre-populated infrastructure and runtime sections. You don’t need to provide a backend information separately in this case.ads operator run -f <operator-type>.yamlAlternatively
ads opctl runcommand can be used:ads opctl run -f <operator-type>.yamlThe operator will be run in chosen environment without requiring additional modifications.
Different Ways To Run Operator¶
To operator can be run in two different ways:
ads operator run -f <operator-config>.yaml
Or alternatively:
ads opctl run -f <operator-config>.yaml
Despite the presented above commands look equivalent, the ads operator run command is more flexible.
Here the few restrictions when running the operator within the ads opctl run command:
The
<operator-config>.yamlfile must contain all the necessary information for running the operator. This means that the<operator-config>.yamlfile must contain theruntimesection describing the backend configuration for the operator.If the
<operator-config>.yamlfile not contains theruntimesection, then theads opctl runcommand can be used in restricted mode with-boption. This option allows you to specify the backend to run the operator on. The-boption can be used with the following backends:local,dataflow,job. However you will not be able to use the-boption with the localcontainerbackend and Data Science Jobscontainerbackend.
Run Operator Locally¶
There are several ways to run the operator in your local environment. The first option is to run it in the environment you’ve prepared on your own, assuming you’ve already installed all the necessary operator packages. The second option is to run the operator within a Docker container, which requires building a Docker image for the operator.
Within Local Environment¶
To run the operator locally, follow these steps:
Create and activate a new conda environment named
<operator-type>.Install all the required libraries listed in the
environment.yamlfile generated by theads operator init --type <operator-type>command.Review the
<operator-type>.yamlfile generated by theads operator initcommand and make necessary adjustments to input and output file locations. Notice that the<operator-type>.yamlwill not be generated if the--merge-configflag is set totrue.Verify the operator’s configuration using the following command:
ads operator verify -f <operator-config>.yaml
To run the operator within the
<operator-type>conda environment, use this command:
ads operator run -f <operator-type>.yaml -b local
The alternative way to run the operator would be to use the ads opctl run command:
ads opctl run -f <operator-type>.yaml -b local
See the Different Ways To Run Operator section for more details.
Within Container¶
To run the operator within a local container, follow these steps:
Build the operator’s container using the following command:
ads operator build-image --type <operator-type>
This command creates a new <operator-type>:<operator-version> image with /etc/operator as the working directory within the container.
Check the
backend_operator_local_container_config.yamlconfiguration file. It should have avolumesection with the.ociconfigs folder mounted, as shown below:
volume:
- "/Users/<user>/.oci:/root/.oci"
Mounting the OCI configs folder is necessary if you intend to use an OCI Object Storage bucket to store input and output data. You can also mount input/output folders to the container as needed.
Following is the YAML schema for validating the runtime YAML using Cerberus:
1kind:
2 allowed:
3 - operator.local
4 required: true
5 type: string
6 meta:
7 description: "The operator local runtime. Kind should always be `operator.local` when using an operator with local container runtime."
8version:
9 allowed:
10 - "v1"
11 required: true
12 type: string
13 meta:
14 description: "Operator local runtime may change yaml file schemas from version to version, as well as implementation details. Double check the version to ensure compatibility."
15type:
16 allowed:
17 - container
18 required: true
19 type: string
20 meta:
21 description: "Type should always be `container` when using an operator with local container runtime."
22spec:
23 required: true
24 type: dict
25 schema:
26 image:
27 nullable: true
28 required: false
29 type: string
30 default: image:tag
31 meta:
32 description: "The image to run the operator. By default will be used the operator name with latest tag."
33 env:
34 nullable: true
35 required: false
36 type: list
37 schema:
38 type: dict
39 schema:
40 name:
41 type: string
42 value:
43 type:
44 - number
45 - string
46 volume:
47 required: false
48 type:
49 - string
50 - list
Run the operator within the container using this command:
ads operator run -f <operator-type>.yaml -b backend_operator_local_container_config.yaml
Or within a short command:
ads operator run -f <operator-type>.yaml -b local.container
The alternative way to run the operator would be to use the ads opctl run command. However in this case the runtime information needs to be merged within operator’s config. See the Different Ways To Run Operator section for more details.
ads opctl run -f <operator-type>.yaml
If the backend runtime information is not merged within operator’s config, then there is no way to run the operator within the ads opctl run command using container runtime. The ads operator run command should be used instead.
Run Operator In Data Science Job¶
Prerequisites
To become proficient with Data Science Jobs, it is recommended to explore their functionality thoroughly. Checking the YAML Schema link will assist you in configuring job YAML specifications more easily in the future.
There are several options for running the operator on the OCI Data Science Jobs service, such as using the python runtime or the Bring Your Own Container (BYOC) approach.
Run With BYOC (Bring Your Own Container)¶
To execute the operator within a Data Science job using container runtime, follow these steps:
Build the container using the following command (you can skip this if you’ve already done it for running the operator within a local container):
ads operator build-image --type <operator-type>
This creates a new <operator-type>:<operator-version> image with /etc/operator as the working directory within the container.
Publish the
<operator-type>:<operator-version>container to the Oracle Container Registry (OCR).
To publish <operator-type>:<operator-version> to OCR, use this command:
ads operator publish-image --type forecast --registry <iad.ocir.io/tenancy/>
After publishing the container to OCR, you can use it within Data Science jobs service. Check the backend_job_container_config.yaml configuration file built during initializing the starter configs for the operator. It should contain pre-populated infrastructure and runtime sections. The runtime section should have an image property, like image: iad.ocir.io/<tenancy>/<operator-type>:<operator-version>.
Adjust the
<operator-type>.yamlconfiguration with the proper input/output folders. When running operator in a Data Science job, it won’t have access to local folders, so input data and output folders should be placed in the Object Storage bucket. Open the<operator-type>.yamland adjust the data path fields.Run the operator on the Data Science jobs using this command:
ads operator run -f <operator-type>.yaml -b backend_job_container_config.yaml
Or within a short command:
ads operator run -f <operator-type>.yaml -b job.container
In this case the backend config will be built on the fly. However the recommended way would be to use explicit configurations for both operator and backend.
The alternative way to run the operator would be to use the ads opctl run command. However in this case the runtime information needs to be merged within operator’s config. See the Different Ways To Run Operator section for more details.
ads opctl run -f <operator-type>.yaml
If the backend runtime information is not merged within operator’s config, then there is no way to run the operator within the ads opctl run command using container runtime. The ads operator run command should be used instead.
You can run the operator within the --dry-run attribute to check the final configs that will be used to run the operator on the service. This command will not run the operator, but will print the final configs that will be used to run the operator on the service.
Running the operator will return a command to help you monitor the job’s logs:
ads opctl watch <OCID>
Run With Conda Environment¶
To execute the operator within a Data Science job using the conda runtime, follow these steps:
Build the operator’s conda environment using this command:
ads operator build-conda --type <operator-type>
This creates a new <operator-type>_<operator-version> conda environment and places it in the folder specified within the ads opctl configure command.
Publish the
<operator-type>_<operator-version>conda environment to the Object Storage bucket using this command:
ads opctl conda publish --slug <operator-type>_<operator-version>
For more details on configuring the CLI, refer to the Explore & Configure Operators documentation.
After publishing the conda environment to Object Storage, you can use it within the Data Science Jobs service. Check the
backend_job_python_config.yamlconfiguration file, which should contain pre-populated infrastructure and runtime sections. The runtime section should include acondasection like this:
conda:
type: published
uri: oci://bucket@namespace/conda_environments/cpu/<operator-type>/<operator-version>/<operator-type>_<operator-version>
Adjust the
<operator-type>.yamlconfiguration with the proper input/output folders. When running the operator in a Data Science job, it won’t have access to local folders, so input data and output folders should be placed in the Object Storage bucket.Run the operator on the Data Science Jobs service using this command:
ads operator run -f <operator-type>.yaml -b backend_job_python_config.yaml
Or within a short command:
ads operator run -f <operator-type>.yaml -b job
In this case the backend config will be built on the fly. However the recommended way would be to use explicit configurations for both operator and backend.
The alternative way to run the operator would be to use the ads opctl run command. However in this case the runtime information needs to be merged within operator’s config. See the Different Ways To Run Operator section for more details.
ads opctl run -f <operator-type>.yaml
Or if the backend runtime information is not merged within operator’s config:
ads opctl run -f <operator-type>.yaml -b job
Monitor the logs using the
ads opctl watchcommand:
ads opctl watch <OCID>
Data Flow Application¶
To execute the operator within a Data Flow application follow these steps:
Build the operator’s conda environment using this command:
ads operator build-conda --type <operator-type>
This creates a new <operator-type>_<operator-version> conda environment and places it in the folder specified within the ads opctl configure command.
Publish the
<operator-type>_<operator-version>conda environment to the Object Storage bucket using this command:
ads operator publish --type <operator-type>
For more details on configuring the CLI, refer to the Explore & Configure Operators documentation.
After publishing the conda environment to Object Storage, you can use it within the Data Flow service. Check the backend_dataflow_dataflow_config.yaml configuration file, which should contain pre-populated infrastructure and runtime sections. The runtime section should include a conda section like this:
conda:
type: published
uri: oci://bucket@namespace/conda_environments/cpu/<operator-type>/<operator-version>/<operator-type>_<operator-version>
Adjust the
<operator-type>.yamlconfiguration with the proper input/output folders. When running the operator in a Data Flow application, it won’t have access to local folders, so input data and output folders should be placed in the Object Storage bucket.Run the operator on the Data Flow service using this command:
ads operator run -f <operator-type>.yaml -b backend_dataflow_dataflow_config.yaml
Or within a short command:
ads operator run -f <operator-type>.yaml -b dataflow
In this case the backend config will be built on the fly. However the recommended way would be to use explicit configurations for both operator and backend.
The alternative way to run the operator would be to use the ads opctl run command. However in this case the runtime information needs to be merged within operator’s config. See the Different Ways To Run Operator section for more details.
ads opctl run -f <operator-type>.yaml
Or if the backend runtime information is not merged within operator’s config:
ads opctl run -f <operator-type>.yaml -b dataflow
Monitor the logs using the
ads opctl watchcommand:
ads opctl watch <OCID>