EmbeddingONNXModel¶
Overview¶
The ads.model.framework.embedding_onnx_model.EmbeddingONNXModel class in ADS is designed to rapidly get an Embedding ONNX Model into production. The .prepare() method creates the model artifacts that are needed without configuring it or writing code. EmbeddingONNXModel supports OpenAI spec for embeddings endpoint.
The .verify() method simulates a model deployment by calling the load_model() and predict() methods in the score.py file. With the .verify() method, you can debug your score.py file without deploying any models. The .save() method deploys a model artifact to the model catalog. The .deploy() method deploys a model to a REST endpoint.
The following steps take the sentence-transformers/all-MiniLM-L6-v2 model and deploy it into production with a few lines of code.
Download Embedding Model from HuggingFace
import tempfile
import os
import shutil
from huggingface_hub import snapshot_download
local_dir = tempfile.mkdtemp()
allow_patterns=[
"onnx/model.onnx",
"config.json",
"special_tokens_map.json",
"tokenizer_config.json",
"tokenizer.json",
"vocab.txt"
]
# download files needed for this demostration to local folder
snapshot_download(
repo_id="sentence-transformers/all-MiniLM-L6-v2",
local_dir=local_dir,
allow_patterns=allow_patterns
)
artifact_dir = tempfile.mkdtemp()
# copy all downloaded files to artifact folder
for file in allow_patterns:
shutil.copy(local_dir + "/" + file, artifact_dir)
Install Conda Pack¶
To deploy the embedding onnx model, start with the onnx conda pack with slug onnxruntime_p311_gpu_x86_64.
odsc conda install -s onnxruntime_p311_gpu_x86_64
Prepare Model Artifact¶
Instantiate an EmbeddingONNXModel() object with Embedding ONNX model. All the model related files will be saved under artifact_dir. ADS will auto generate the score.py and runtime.yaml that are required for the deployment.
For more detailed information on what parameters that EmbeddingONNXModel takes, refer to the API Documentation
import ads
from ads.model import EmbeddingONNXModel
# other options are `api_keys` or `security_token` depending on where the code is executed
ads.set_auth("resource_principal")
embedding_onnx_model = EmbeddingONNXModel(artifact_dir=artifact_dir)
embedding_onnx_model.prepare(
inference_conda_env="onnxruntime_p311_gpu_x86_64",
inference_python_version="3.11",
model_file_name="model.onnx",
force_overwrite=True
)
Summary Status¶
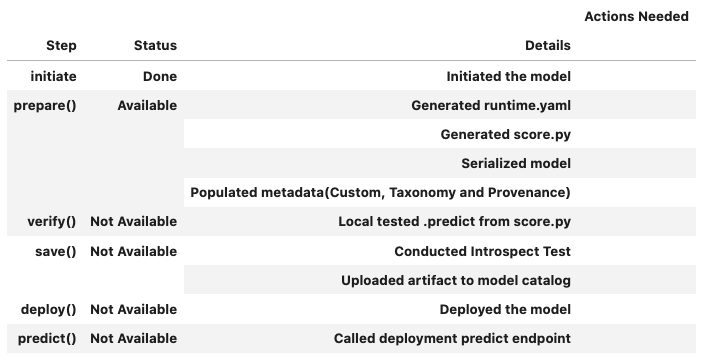
You can call the .summary_status() method after a model serialization instance such as GenericModel, SklearnModel, TensorFlowModel, EmbeddingONNXModel, or PyTorchModel is created. The .summary_status() method returns a Pandas dataframe that guides you through the entire workflow. It shows which methods are available to call and which ones aren’t. Plus it outlines what each method does. If extra actions are required, it also shows those actions.
The following image displays an example summary status table created after a user initiates a model instance. The table’s Step column displays a Status of Done for the initiate step. And the Details column explains what the initiate step did such as generating a score.py file. The Step column also displays the prepare(), verify(), save(), deploy(), and predict() methods for the model. The Status column displays which method is available next. After the initiate step, the prepare() method is available. The next step is to call the prepare() method.
Verify Model¶
Call the verify() to check if the model can be executed locally.
embedding_onnx_model.verify(
{
"input": ['What are activation functions?', 'What is Deep Learning?'],
"model": "sentence-transformers/all-MiniLM-L6-v2"
},
)
If successful, similar results as below should be presented.
{
'object': 'list',
'data':
[{
'object': 'embedding',
'embedding':
[[
-0.11011122167110443,
-0.39235609769821167,
0.38759472966194153,
-0.34653618931770325,
...,
]]
}]
}
Register Model¶
Save the model artifacts and create an model entry in OCI DataScience Model Catalog.
embedding_onnx_model.save(display_name="sentence-transformers/all-MiniLM-L6-v2")
Deploy and Generate Endpoint¶
Create a model deployment from the embedding onnx model in Model Catalog. The process takes several minutes and the deployment configurations will be presented once it’s completed.
embedding_onnx_model.deploy(
display_name="all-MiniLM-L6-v2 Embedding Model Deployment",
deployment_log_group_id="<log_group_id>",
deployment_access_log_id="<access_log_id>",
deployment_predict_log_id="<predict_log_id>",
deployment_instance_shape="VM.Standard.E4.Flex",
deployment_ocpus=20,
deployment_memory_in_gbs=256,
)
Run Prediction against Endpoint¶
Call predict() to check the model deployment endpoint.
embedding_onnx_model.predict(
{
"input": ["What are activation functions?", "What is Deep Learning?"],
"model": "sentence-transformers/all-MiniLM-L6-v2"
},
)
If successful, similar results as below should be presented.
{
'object': 'list',
'data':
[{
'object': 'embedding',
'embedding':
[[
-0.11011122167110443,
-0.39235609769821167,
0.38759472966194153,
-0.34653618931770325,
...,
]]
}]
}
Run Prediction with OCI CLI¶
Model deployment endpoints can also be invoked with the OCI CLI.
oci raw-request --http-method POST --target-uri <deployment_endpoint> --request-body '{"input": ["What are activation functions?", "What is Deep Learning?"], "model": "sentence-transformers/all-MiniLM-L6-v2"}' --auth resource_principal
Example¶
import tempfile
import os
import shutil
import ads
from ads.model import EmbeddingONNXModel
from huggingface_hub import snapshot_download
# other options are `api_keys` or `security_token` depending on where the code is executed
ads.set_auth("resource_principal")
local_dir = tempfile.mkdtemp()
allow_patterns=[
"onnx/model.onnx",
"config.json",
"special_tokens_map.json",
"tokenizer_config.json",
"tokenizer.json",
"vocab.txt"
]
# download files needed for this demostration to local folder
snapshot_download(
repo_id="sentence-transformers/all-MiniLM-L6-v2",
local_dir=local_dir,
allow_patterns=allow_patterns
)
artifact_dir = tempfile.mkdtemp()
# copy all downloaded files to artifact folder
for file in allow_patterns:
shutil.copy(local_dir + "/" + file, artifact_dir)
# initialize EmbeddingONNXModel instance and prepare score.py, runtime.yaml and openapi.json files.
embedding_onnx_model = EmbeddingONNXModel(artifact_dir=artifact_dir)
embedding_onnx_model.prepare(
inference_conda_env="onnxruntime_p311_gpu_x86_64",
inference_python_version="3.11",
model_file_name="model.onnx",
force_overwrite=True
)
# validates model locally
embedding_onnx_model.verify(
{
"input": ['What are activation functions?', 'What is Deep Learning?'],
"model": "sentence-transformers/all-MiniLM-L6-v2"
},
)
# save model to oci model catalog
embedding_onnx_model.save(display_name="sentence-transformers/all-MiniLM-L6-v2")
# deploy model
embedding_onnx_model.deploy(
display_name="all-MiniLM-L6-v2 Embedding Model Deployment",
deployment_log_group_id="<log_group_id>",
deployment_access_log_id="<access_log_id>",
deployment_predict_log_id="<predict_log_id>",
deployment_instance_shape="VM.Standard.E4.Flex",
deployment_ocpus=20,
deployment_memory_in_gbs=256,
)
# check model deployment endpoint
embedding_onnx_model.predict(
{
"input": ["What are activation functions?", "What is Deep Learning?"],
"model": "sentence-transformers/all-MiniLM-L6-v2"
},
)