GenericModel¶
Overview¶
The GenericModel class in ADS provides an efficient way to serialize almost any model class. This section demonstrates how to use the GenericModel class to prepare model artifacts, verify models, save models to the model catalog, deploy models, and perform predictions on model deployment endpoints.
The GenericModel class works with any unsupported model framework that has a .predict() method. For the most common model classes such as scikit-learn, XGBoost, LightGBM, TensorFlow, and PyTorch, we recommend that you use the ADS provided, framework-specific serializations models. For example, for a scikit-learn model, use SKLearnmodel. For other models, use the GenericModel class.
The .verify() method simulates a model deployment by calling the load_model() and predict() methods in the score.py file. With the .verify() method, you can debug your score.py file without deploying any models. The .save() method deploys a model artifact to the model catalog. The .deploy() method deploys a model to a REST endpoint.
These simple steps take your trained model and will deploy it into production with just a few lines of code.
Initialize¶
Instantiate a GenericModel() object by giving it any model object. It accepts the following parameters:
artifact_dir: str: Artifact directory to store the files needed for deployment.auth: (Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. To override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal()and create the appropriate authentication signer and the**kwargsrequired to instantiate theIdentityClientobject.estimator: (Callable): Trained model.properties: (ModelProperties, optional): Defaults toNone. ModelProperties object required to save and deploy the model.serialize: (bool, optional): Defaults toTrue. IfTruethe model will be serialized into a pickle file. IfFalse, you must set themodel_file_namein the.prepare()method, serialize the model manually, and save it in theartifact_dir. You will also need to update thescore.pyfile to work with this model.
The properties is an instance of the ModelProperties class and has the following predefined fields:
bucket_uri(str):compartment_id(str):deployment_access_log_id(str):deployment_bandwidth_mbps(int):deployment_instance_count(int):deployment_instance_shape(str):deployment_log_group_id(str):deployment_predict_log_id(str):inference_conda_env(str):inference_python_version(str):overwrite_existing_artifact(bool):project_id(str):remove_existing_artifact(bool):training_conda_env(str):training_id(str):training_python_version(str):training_resource_id(str):training_script_path(str):
By default, properties is populated from the environment variables when not specified. For example, in notebook sessions the environment variables are preset and stored in project id (PROJECT_OCID) and compartment id (NB_SESSION_COMPARTMENT_OCID). So ``properties populates these environment variables, and uses the values in methods such as .save() and .deploy(). Pass in values to overwrite the defaults. When you use a method that includes an instance of properties, then properties records the values that you pass in. For example, when you pass inference_conda_env into the .prepare() method, then properties records the value. To reuse the properties file in different places, you can export the properties file using the .to_yaml() method then reload it into a different machine using the .from_yaml() method.
Summary Status¶
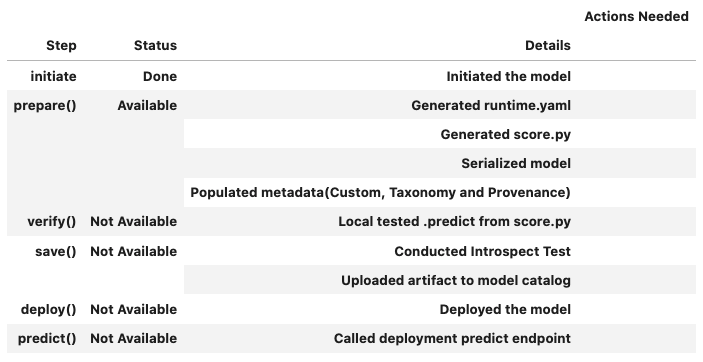
You can call the .summary_status() method after a model serialization instance such as GenericModel, SklearnModel, TensorFlowModel, or PyTorchModel is created. The .summary_status() method returns a Pandas dataframe that guides you through the entire workflow. It shows which methods are available to call and which ones aren’t. Plus it outlines what each method does. If extra actions are required, it also shows those actions.
The following image displays an example summary status table created after a user initiates a model instance. The table’s Step column displays a Status of Done for the initiate step. And the Details column explains what the initiate step did such as generating a score.py file. The Step column also displays the prepare(), verify(), save(), deploy(), and predict() methods for the model. The Status column displays which method is available next. After the initiate step, the prepare() method is available. The next step is to call the prepare() method.
Model Deployment¶
Prepare¶
The prepare step is performed by the .prepare() method. It creates several customized files used to run the model after it is deployed. These files include:
input_schema.json: A JSON file that defines the nature of the feature data. It includes information about the features. This includes metadata such as the data type, name, constraints, summary statistics, feature type, and more.model.pkl: This is the default filename of the serialized model. It can be changed with themodel_file_nameattribute. By default, the model is stored in a pickle file. The parameteras_onnxcan be used to save it in the ONNX format.output_schema.json: A JSON file that defines the nature of the dependent variable. This includes metadata such as the data type, name, constraints, summary statistics, feature type, and more.runtime.yaml: This file contains information that is needed to set up the runtime environment on the deployment server. It has information about which conda environment was used to train the model, and what environment should be used to deploy the model. The file also specifies what version of Python should be used.score.py: This script contains theload_model()andpredict()functions. Theload_model()function understands the format the model file was saved in and loads it into memory. Thepredict()function is used to make inferences in a deployed model. There are also hooks that allow you to perform operations before and after inference. You are able to modify this script to fit your specific needs.
To create the model artifacts, use the .prepare() method. The .prepare() method includes parameters for storing model provenance information.
The .prepare() method serializes the model and prepares and saves the score.py and runtime.yaml files using the following parameters:
as_onnx(bool, optional): Defaults toFalse. IfTrue, it will serialize as an ONNX model.force_overwrite(bool, optional): Defaults toFalse. IfTrue, it will overwrite existing files.ignore_pending_changes(bool): Defaults toFalse. IfFalse, it will ignore the pending changes in Git.inference_conda_env(str, optional): Defaults toNone. Can be either slug or the Object Storage path of the conda environment. You can only pass in slugs if the conda environment is a Data Science service environment.inference_python_version(str, optional): Defaults toNone. The version of Python to use in the model deployment.max_col_num(int, optional): Defaults toutils.DATA_SCHEMA_MAX_COL_NUM. Do not automatically generate the input schema if the input data has more than this number of features.model_file_name(str): Name of the serialized model.namespace(str, optional): Namespace of the OCI region. This is used for identifying which region the service environment is from when you provide a slug to theinference_conda_envortraining_conda_envparameters.training_conda_env(str, optional): Defaults toNone. Can be either slug or object storage path of the conda environment that was used to train the model. You can only pass in a slug if the conda environment is a Data Science service environment.training_id(str, optional): Defaults to value from environment variables. The training OCID for the model. Can be a notebook session or job OCID.training_python_version(str, optional): Defaults to None. The version of Python used to train the model.training_script_path(str): Defaults toNone. The training script path.use_case_type(str): The use case type of the model. Use it with theUserCaseTypeclass or the string provided inUseCaseType. For example,use_case_type=UseCaseType.BINARY_CLASSIFICATIONoruse_case_type="binary_classification", see theUseCaseTypeclass to see all supported types.X_sample(Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]): Defaults toNone. A sample of the input data. It is used to generate the input schema.y_sample(Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]): Defaults to None. A sample of output data. It is used to generate the output schema.**kwarg:impute_values(dict, optional): The dictionary where the key is the column index (or names is accepted for Pandas dataframe), and the value is the imputed value for the corresponding column.
Added in version 2.6.3.
If you run the code using a service conda pack in a notebook session, you do not need to pass inference_conda_env. The .prepare() method automatically tries to detect the conda environment.
Verify¶
If you update the score.py file included in a model artifact, you can verify your changes, without deploying the model. With the .verify() method, you can debug your code without having to save the model to the model catalog and then deploying it. The .verify() method takes a set of test parameters and performs the prediction by calling the predict() function in score.py. It also runs the load_model() function to load the model.
The verify() method tests whether the .predict() API works in the local environment and it takes the following parameter:
data (Union[dict, str, tuple, list, bytes]). The data is used to test if the deployment works in the local environment.
In GenericModel, data serialization is not supported. You can implement data serialization and deserialization in the score.py file.
Save¶
After you are satisfied with the performance of your model and have verified that the score.py file is working, use the .save() method to save the model to the model catalog. The .save() method bundles up the model artifacts, stores them in the model catalog, and returns the model OCID.
The .save() method stores the model artifacts in the model catalog. It takes the following parameters:
bucket_uri(str, optional). Defaults toNone. The OCI Object Storage URI where model artifacts aree copied to. Thebucket_uriis only necessary for uploading large artifacts with size greater than 2 GB. For example,oci://<bucket_name>@<namespace>/prefix/.defined_tags(Dict(str, dict(str, object)), optional): Defaults toNone. Defined tags for the model.description(str, optional): Defaults toNone. The description of the model.display_name(str, optional): Defaults toNone. The name of the model.freeform_tagsDict(str, str): Defaults toNone. Free form tags for the model.ignore_introspection(bool, optional): Defaults toNone. Determines whether to ignore the result of model introspection or not. If set toTrue, then.save()ignores all model introspection errors.overwrite_existing_artifact(bool, optional). Defaults toTrue. Overwrite target bucket artifact if exists.remove_existing_artifact(bool, optional). Defaults toTrue. Whether artifacts uploaded to the Object Storage bucket is removed or not.**kwargs:compartment_id(str, optional): Compartment OCID. If not specified, the value is taken either from the environment variables or model properties.project_id(str, optional): Project OCID. If not specified, the value is taken either from the environment variables or model properties.timeout(int, optional): Defaults to 10 seconds. The connection timeout in seconds for the client.
The .save() method reloads score.py and runtime.yaml files from disk to find any changes that have been made to the files. If ignore_introspection=False, then it conducts an introspection test to determine if the model deployment may have issues. If potential problems are detected, it suggests possible remedies. Lastly, it uploads the artifacts to the model catalog and returns the model OCID. You can also call .instrospect() to conduct the test any time after you call .prepare().
Deploy¶
You can use the .deploy() method to deploy a model. You must first save the model to the model catalog, and then deploy it.
The .deploy() method returns a ModelDeployment object. Specify deployment attributes such as display name, instance type, number of instances, maximum router bandwidth, and logging groups. The API takes the following parameters:
deployment_access_log_id(str, optional): Defaults toNone. The access log OCID for the access logs, see logging.deployment_bandwidth_mbps(int, optional): Defaults to 10. The bandwidth limit on the load balancer in Mbps.deployment_instance_count(int, optional): Defaults to 1. The number of instances used for deployment.deployment_instance_shape(str, optional): Default to VM.Standard2.1. The shape of the instance used for deployment.deployment_log_group_id(str, optional): Defaults toNone. The OCI logging group OCID. The access log and predict log share the same log group.deployment_predict_log_id(str, optional): Defaults toNone. The predict log OCID for the predict logs, see logging.description(str, optional): Defaults toNone. The description of the model.display_name(str, optional): Defaults toNone. The name of the model.wait_for_completion(bool, optional): Defaults toTrue. Set to wait for the deployment to complete before proceeding.**kwargs:compartment_id(str, optional): Compartment OCID. If not specified, the value is taken from the environment variables.max_wait_time(int, optional): Defaults to 1200 seconds. The maximum amount of time to wait in seconds. A negative value implies an infinite wait time.poll_interval(int, optional): Defaults to 60 seconds. Poll interval in seconds.project_id(str, optional): Project OCID. If not specified, the value is taken from the environment variables.
Prepare, Save and Deploy Shortcut¶
Added in version 2.6.3.
The .prepare_save_deploy() method is a shortcut for the functions .prepare(), .save(), and .deploy(). This method returns a ModelDeployment object and is available for all frameworks. The method takes the following parameters:
inference_conda_env: (str, optional). Defaults to None.Can either be a slug or an object storage path for the conda pack. You can only pass in slugs if the conda pack is a service pack.
inference_python_version: (str, optional). Defaults to None.The Python version to use in the deployment.
training_conda_env: (str, optional). Defaults to None.Can either be a slug or an object storage path for the conda pack. You can only pass in slugs if the conda pack is a service pack.
training_python_version: (str, optional). Defaults to None.Python version to use for training.
model_file_name: (str).Name of the serialized model.
as_onnx: (bool, optional). Defaults to False.Whether to serialize as ONNX model.
initial_types: (list[Tuple], optional).Defaults to None. Only used for SklearnModel, LightGBMModel and XGBoostModel. Each element is a tuple of a variable name and a type. Check this link http://onnx.ai/sklearn-onnx/api_summary.html#id2> for explanations and examples for
initial_types.
force_overwrite: (bool, optional). Defaults to False.Whether to overwrite existing files.
namespace: (str, optional).Namespace of region. Use this parameter to identify the service pack region when you pass a slug to
inference_conda_envandtraining_conda_env.
use_case_type: strThe use case type of the model. Assign a value using the
UseCaseTypeclass or provide a string inUseCaseType. For example, use_case_type=UseCaseType.BINARY_CLASSIFICATION or use_case_type=”binary_classification”. Check theUseCaseTypeclass to see supported types.
X_sample: Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]. Defaults to None.A sample of input data used to generate input schema.
y_sample: Union[list, tuple, pd.Series, np.ndarray, pd.DataFrame]. Defaults to None.A sample of output data used to generate output schema.
training_script_path: str. Defaults to None.Training script path.
training_id: (str, optional). Defaults to value from environment variables.The training OCID for model. Can be notebook session or job OCID.
ignore_pending_changes: bool. Defaults to False.Whether to ignore pending changes in git.
max_col_num: (int, optional). Defaults toutils.DATA_SCHEMA_MAX_COL_NUM.Do not generate the input schema if the input has more than this number of features(columns).
model_display_name: (str, optional). Defaults to None.The name of the model.
model_description: (str, optional). Defaults to None.The description of the model.
model_freeform_tagsDict(str, str), Defaults to None.Freeform tags for the model.
model_defined_tags(Dict(str, dict(str, object)), optional). Defaults to None.Defined tags for the model.
ignore_introspection: (bool, optional). Defaults to None.Determine whether to ignore the result of model introspection or not. If set to True, the save will ignore all model introspection errors.
wait_for_completion(bool, optional). Defaults to True.Determine whether to wait for deployment to complete before proceeding.
display_name: (str, optional). Defaults to None.The name of the model.
description: (str, optional). Defaults to None.The description of the model.
deployment_instance_shape: (str, optional).The shape of the instance used for deployment.
deployment_instance_count: (int, optional). Defaults to 1.The number of instances used for deployment.
deployment_bandwidth_mbps: (int, optional). Defaults to 10.The bandwidth limit on the load balancer in Mbps.
deployment_log_group_id: (str, optional). Defaults to None.The oci logging group id. The access log and predict log share the same log group.
deployment_access_log_id: (str, optional). Defaults to None.The access log OCID for the access logs. https://docs.oracle.com/iaas/data-science/using/model_dep_using_logging.htm>
deployment_predict_log_id: (str, optional). Defaults to None.The predict log OCID for the predict logs. https://docs.oracle.com/iaas/data-science/using/model_dep_using_logging.htm>
kwargs:impute_values: (dict, optional).The dictionary where the key is the column index (or names is accepted for pandas dataframe) and the value is the impute value for the corresponding column.
project_id: (str, optional).Project OCID. If not specified, gets the value either from the environment variables or model properties.
compartment_id(str, optional).Compartment OCID. If not specified, gets the value either from the environment variables or model properties.
timeout: (int, optional). Defaults to 10 seconds.The connection timeout in seconds for the client.
max_wait_time(int, optional). Defaults to 1200 seconds.Maximum amount of time to wait in seconds. Negative values imply infinite wait time.
poll_interval(int, optional). Defaults to 60 seconds.Poll interval in seconds.
Predict¶
To get a prediction for your model, after your model deployment is active, call the .predict() method. The .predict() method sends a request to the deployed endpoint, and computes the inference values based on the data that you input in the .predict() method.
The .predict() method returns a prediction of input data that is run against the model deployment endpoint and takes the following parameters:
data: Union[dict, str, tuple, list]: JSON serializable data used for making inferences.
The .predict() and .verify() methods take the same data formats.
score.py¶
In the prepare step, the service automatically generates a score.py file in the artifact directory.
The score.py consists of a bunch of functions among which the load_model and predict are most important.
load_model¶
During deployment, the load_model method loads the serialized model. The load_model method is always fully populated, except when you set serialize=False for GenericModel.
For the
GenericModelclass, if you chooseserialize=Truein the init function, the model is pickled and thescore.pyis fully auto-populated to support loading the pickled model.
Otherwise, the user is responsible to fill the
load_model.
For other frameworks, this part is fully populated.
predict¶
The predict method is triggered every time a payload is sent to the model deployment endpoint. The method takes the payload and the loaded model as inputs. Based on the payload, the method returns the predicted results output by the model.
pre_inference¶
If the payload passed to the endpoint needs preprocessing, this function does the preprocessing step. The user is fully responsible for the preprocessing step.
post_inference¶
If the predicted result from the model needs some postprocessing, the user can put the logic in this function.
deserialize¶
When you use the .verify() or .predict() methods from model classes such as GenericModel or SklearnModel, if the data passed in is not in bytes or JsonSerializable, the models try to serialize the data. For example, if a pandas dataframe is passed and not accepted by the deployment endpoint, the pandas dataframe is converted to JSON internally. When the X_sample variable is passed into the .prepare() function, the data type of pandas dataframe is passed to the endpoint, and the schema of the dataframe is recorded in the input_schema.json file. Then, the JSON payload is sent to the endpoint. Because the model expects to take a pandas dataframe, the .deserialize() method converts the JSON back to the pandas dataframe using the schema and the data type. For all frameworks except for the GenericModel class, the .deserialize() method is auto-populated. Note that for each framework, only specific data types are supported.
Starting from .. versionadded:: 2.6.3, you can send the bytes to the endpoint directly. If the bytes payload is sent to the endpoint, bytes are passed directly to the model. If the model expects a specific data format, you need to write the conversion logic yourself.
fetch_data_type_from_schema¶
This function is used to load the schema from the input_schema.json when needed.
Load¶
You can restore serialization models from model artifacts, from model deployments or from models in the model catalog. This section provides details on how to restore serialization models.
Model Artifact¶
A model artifact is a collection of files used to create a model deployment. Some example files included in a model artifact are the serialized model, score.py, and runtime.yaml. You can store your model artifact in a local directory, in a ZIP or TAR format. Then use the .from_model_artifact() method to import the model artifact into the serialization model class. The .from_model_artifact() method takes the following parameters:
artifact_dir(str): Artifact directory to store the files needed for deployment.auth(Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. To override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal()and create the appropriate authentication signer and the**kwargsrequired to instantiate theIdentityClientobject.force_overwrite(bool, optional): Defaults toFalse. IfTrue, it will overwrite existing files.model_file_name(str): The serialized model file name.properties(ModelProperties, optional): Defaults toNone.ModelPropertiesobject required to save and deploy the model.uri(str): The path to the folder, ZIP, or TAR file that contains the model artifact. The model artifact must contain the serialized model, thescore.py,runtime.yamland other files needed for deployment. The content of the URI is copied to theartifact_dirfolder.
from ads.model.generic_model import GenericModel
model = GenericModel.from_model_artifact(
uri="/folder_to_your/artifact.zip",
model_file_name="model.pkl",
artifact_dir="/folder_store_artifact"
)
Model Catalog¶
To populate a serialization model object from a model stored in the model catalog, call the .from_model_catalog() method. This method uses the model OCID to download the model artifacts, write them to the artifact_dir, and update the serialization model object. The .from_model_catalog() method takes the following parameters:
artifact_dir(str): Artifact directory to store the files needed for deployment.auth(Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. To override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal()and create the appropriate authentication signer and the**kwargsrequired to instantiate theIdentityClientobject.bucket_uri(str, optional). Defaults toNone. The OCI Object Storage URI where model artifacts will be copied to. Thebucket_uriis only necessary for uploading large artifacts with size greater than 2GB. Example:oci://<bucket_name>@<namespace>/prefix/.force_overwrite(bool, optional): Defaults toFalse. IfTrue, it will overwrite existing files.model_id(str): The model OCID.model_file_name(str): The serialized model file name.overwrite_existing_artifact(bool, optional). Defaults toTrue. Overwrite target bucket artifact if exists.properties(ModelProperties, optional): Defaults to None. Define the properties to save and deploy the model.**kwargs:compartment_id(str, optional): Compartment OCID. If not specified, the value will be taken from the environment variables.timeout(int, optional): Defaults to 10 seconds. The connection timeout in seconds for the client.
from ads.model.generic_model import GenericModel
model = GenericModel.from_model_catalog(model_id="<model_id>",
model_file_name="model.pkl",
artifact_dir=tempfile.mkdtemp())
Model Deployment¶
Added in version 2.6.2.
To populate a serialization model object from a model deployment, call the .from_model_deployment() method. This method accepts a model deployment OCID. It downloads the model artifacts, writes them to the model artifact directory (artifact_dir), and updates the serialization model object. The .from_model_deployment() method takes the following parameters:
artifact_dir(str): Artifact directory to store the files needed for deployment.auth(Dict, optional): Defaults toNone. The default authentication is set using theads.set_authAPI. To override the default, useads.common.auth.api_keys()orads.common.auth.resource_principal(). Supply the appropriate authentication signer and the**kwargsrequired to instantiate anIdentityClientobject.bucket_uri(str, optional). Defaults toNone. The OCI Object Storage URI where model artifacts are copied to. Thebucket_uriis only necessary for uploading large artifacts with size greater than 2 GB. For example,oci://<bucket_name>@<namespace>/prefix/.force_overwrite(bool, optional): Defaults toFalse. IfTrue, it will overwrite existing files in the artifact directory.model_deployment_id(str): The model deployment OCID.model_file_name(str): The serialized model file name.overwrite_existing_artifact(bool, optional). Defaults toTrue. Overwrite target bucket artifact if exists.properties(ModelProperties, optional): Defaults toNone. Define the properties to save and deploy the model.**kwargs:compartment_id(str, optional): Compartment OCID. If not specified, the value will be taken from the environment variables.timeout(int, optional): Defaults to 10 seconds. The connection timeout in seconds for the client.
from ads.model.generic_model import GenericModel
model = GenericModel.from_model_deployment(
model_deployment_id="<model_deployment_id>",
model_file_name="model.pkl",
artifact_dir=tempfile.mkdtemp())
Delete a Deployment¶
Use the .delete_deployment() method on the serialization model object to delete a model deployment. You must delete a model deployment before deleting its associated model from the model catalog.
Each time you call the .deploy() method, it creates a new deployment. Only the most recent deployment is attached to the object.
The .delete_deployment() method deletes the most recent deployment and takes the following optional parameter:
wait_for_completion: (bool, optional). Defaults toFalseand the process runs in the background. If set toTrue, the method returns when the model deployment is deleted.
Example¶
By default, the GenericModel serializes to a pickle file. The following example, the user creates a model. In the prepare step, the user saves the model as a pickle file with the name toy_model.pkl. Then the user verifies the model, saves it to the model catalog, deploys the model and makes a prediction. Finally, the user deletes the model deployment and then deletes the model.
import tempfile
import ads
from ads.model.generic_model import GenericModel
from catboost import CatBoostRegressor
ads.set_auth(auth="resource_principal")
# Initialize data
X_train = [[1, 4, 5, 6],
[4, 5, 6, 7],
[30, 40, 50, 60]]
X_test = [[2, 4, 6, 8],
[1, 4, 50, 60]]
y_train = [10, 20, 30]
# Initialize CatBoostRegressor
catboost_estimator = CatBoostRegressor(iterations=2,
learning_rate=1,
depth=2)
# Train a CatBoostRegressor model
catboost_estimator.fit(X_train, y_train)
# Get predictions
preds = catboost_estimator.predict(X_test)
# Instantiate ads.model.generic_model.GenericModel using the trained Custom Model using the trained CatBoost Classifier model
catboost_model = GenericModel(estimator=catboost_estimator,
artifact_dir=tempfile.mkdtemp(),
model_save_serializer="cloudpickle",
model_input_serializer="json")
# Autogenerate score.py, pickled model, runtime.yaml, input_schema.json and output_schema.json
catboost_model.prepare(
inference_conda_env="oci://bucket@namespace/path/to/your/conda/pack",
inference_python_version="your_python_version",
X_sample=X_train,
y_sample=y_train,
)
# Verify generated artifacts. Payload looks like this: [[2, 4, 6, 8], [1, 4, 50, 60]]
catboost_model.verify(X_test, auto_serialize_data=True)
# Register CatBoostRegressor model
model_id = catboost_model.save(display_name="CatBoost Model")
catboost_model.deploy()
catboost_model.predict(X_test)
catboost_model.delete_deployment(wait_for_completion=True)
catboost_model.delete() # delete the model
Example – Save Your Own Model¶
By default, the serialize in GenericModel class is True, and it will serialize the model using cloudpickle. However, you can set serialize=False to disable it. And serialize the model on your own. You just need to copy the serialized model into the .artifact_dir. This example shows step by step how you can do that.
The example is illustrated using a Sklearn model.
Warning
This section describes trusted model artifact serialization. Do not use
cloudpickle-serialized objects as /predict request payloads. For model
deployment input, prefer JSON-compatible serializers. ADS-generated scoring
artifacts do not deserialize cloudpickle request payloads. If you need a
different request format for a trusted private workflow, provide and review
a custom score.py implementation.
import tempfile
from ads import set_auth
from ads.model import GenericModel
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
set_auth(auth="resource_principal")
# Load dataset and Prepare train and test split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
# Train a LogisticRegression model
sklearn_estimator = LogisticRegression()
sklearn_estimator.fit(X_train, y_train)
# Serialize your model. You can choose your own way to serialize your model.
import cloudpickle
with open("./model.pkl", "wb") as f:
cloudpickle.dump(sklearn_estimator, f)
model = GenericModel(sklearn_estimator, artifact_dir = "model_artifact_folder", serialize=False)
model.prepare(inference_conda_env="generalml_p38_cpu_v1",force_overwrite=True, model_file_name="model.pkl", X_sample=X_test)
Now copy the model.pkl file and paste into the model_artifact_folder folder. And open the score.py in the model_artifact_folder folder to add implementation of the load_model function. You can also add your preprocessing steps in pre_inference function and postprocessing steps in post_inference function. Below is an example implementation of the score.py.
Replace your score.py with the code below.
# score.py 1.0 generated by ADS 2.8.2 on 20230301_065458
import os
import sys
import json
from functools import lru_cache
model_name = 'model.pkl'
"""
Inference script. This script is used for prediction by scoring server when schema is known.
"""
@lru_cache(maxsize=10)
def load_model(model_file_name=model_name):
"""
Loads model from the serialized format
Returns
-------
model: a model instance on which predict API can be invoked
"""
model_dir = os.path.dirname(os.path.realpath(__file__))
if model_dir not in sys.path:
sys.path.insert(0, model_dir)
contents = os.listdir(model_dir)
if model_file_name in contents:
import cloudpickle
with open(os.path.join(model_dir, model_name), "rb") as f:
model = cloudpickle.load(f)
return model
else:
raise Exception(f'{model_file_name} is not found in model directory {model_dir}')
@lru_cache(maxsize=1)
def fetch_data_type_from_schema(input_schema_path=os.path.join(os.path.dirname(os.path.realpath(__file__)), "input_schema.json")):
"""
Returns data type information fetch from input_schema.json.
Parameters
----------
input_schema_path: path of input schema.
Returns
-------
data_type: data type fetch from input_schema.json.
"""
data_type = {}
if os.path.exists(input_schema_path):
schema = json.load(open(input_schema_path))
for col in schema['schema']:
data_type[col['name']] = col['dtype']
else:
print("input_schema has to be passed in in order to recover the same data type. pass `X_sample` in `ads.model.framework.sklearn_model.SklearnModel.prepare` function to generate the input_schema. Otherwise, the data type might be changed after serialization/deserialization.")
return data_type
def deserialize(data, input_schema_path):
"""
Deserialize json serialization data to data in original type when sent to predict.
Parameters
----------
data: serialized input data.
input_schema_path: path of input schema.
Returns
-------
data: deserialized input data.
"""
import pandas as pd
import numpy as np
import base64
from io import BytesIO
if isinstance(data, bytes):
return data
data_type = data.get('data_type', '') if isinstance(data, dict) else ''
json_data = data.get('data', data) if isinstance(data, dict) else data
if "numpy.ndarray" in data_type:
load_bytes = BytesIO(base64.b64decode(json_data.encode('utf-8')))
return np.load(load_bytes, allow_pickle=False)
if "pandas.core.series.Series" in data_type:
return pd.Series(json_data)
if "pandas.core.frame.DataFrame" in data_type or isinstance(json_data, str):
return pd.read_json(json_data, dtype=fetch_data_type_from_schema(input_schema_path))
if isinstance(json_data, dict):
return pd.DataFrame.from_dict(json_data)
return json_data
def pre_inference(data, input_schema_path):
"""
Preprocess data
Parameters
----------
data: Data format as expected by the predict API of the core estimator.
input_schema_path: path of input schema.
Returns
-------
data: Data format after any processing.
"""
return deserialize(data, input_schema_path)
def post_inference(yhat):
"""
Post-process the model results
Parameters
----------
yhat: Data format after calling model.predict.
Returns
-------
yhat: Data format after any processing.
"""
return yhat.tolist()
def predict(data, model=load_model(), input_schema_path=os.path.join(os.path.dirname(os.path.realpath(__file__)), "input_schema.json")):
"""
Returns prediction given the model and data to predict
Parameters
----------
model: Model instance returned by load_model API.
data: Data format as expected by the predict API of the core estimator. For eg. in case of sckit models it could be numpy array/List of list/Pandas DataFrame.
input_schema_path: path of input schema.
Returns
-------
predictions: Output from scoring server
Format: {'prediction': output from model.predict method}
"""
features = pre_inference(data, input_schema_path)
yhat = post_inference(
model.predict(features)
)
return {'prediction': yhat}
Save the score.py and now call .verify() to check if it works locally.
model.verify(X_test[:2], auto_serialize_data=True)
After verify run successfully, you can save the model to model catalog, deploy and call predict to invoke the endpoint.
model_id = model.save(display_name='Demo Sklearn model')
deploy = model.deploy(display_name='Demo Sklearn deployment')
model.predict(X_test[:2].tolist())
You can also use the shortcut .prepare_save_deploy() instead of calling .prepare(), .save() and .deploy() seperately.
import tempfile
from ads.catalog.model import ModelCatalog
from ads.model.generic_model import GenericModel
class Toy:
def predict(self, x):
return x ** 2
estimator = Toy()
model = GenericModel(estimator=estimator)
model.summary_status()
# If you are running the code inside a notebook session and using a service pack, `inference_conda_env` can be omitted.
model.prepare_save_deploy(inference_conda_env="dataexpl_p37_cpu_v3")
model.verify(2)
model.predict(2)
model.delete_deployment(wait_for_completion=True)
model.delete()